
Das knuddelige Observium Maskottchen(tm)
Wer kennt sie nicht, die Qual der Wahl.
Monitoring und Graphing Werkzeuge gibt es zuhauf und jedes hat seine eigenen Vorzüge und Besonderheiten. Man hat meist die Wahl zwischen den „full blown“ Enterprise Tools wie HP OpenView und Solarwinds, den „Schweizer Bastelmessern“ wie Nagios & Friends oder anschaulichen Nischenlösungen wie PRTG. Viele dieser traditionellen Tools haben oftmals die Eigenschaft, dass erhebliche Anpassungen und Konfigurationsarbeiten im Tool von Nöten sind, um die gewünschten Erfolge zu erzielen.
Heute wollen wir euch einen weiteren Kandidaten für die „Qual der Wahl“ vorstellen, der oftmals im „Enterprise Umfeld“ noch nicht weit bekannt ist und gerade bei der Überwachung von großen, heterogenen Netzwerken seine Stärken ausspielen kann: Observium.
01: Was ist Observium?
Observium hat den Anspruch eine intuitive Multiplattform Netzwerküberwachungsplattform zu sein, welche alle großen und auch viele kleine Hersteller und Geräte ohne Individualisierungsaufwand unterstützt.
Eigentliche Zielgruppe des Produkts sind Serviceprovider, jedoch kann man Observium auch sehr gut im „Enterprise Umfeld“ einsetzen, da es inzwischen die dazu nötige Reife erreicht hat.
Observium gibt es in einer halbjährlich veröffentlichten, freien Version mit leicht reduzierten Features (Alarmierung, Gruppen, …) und eine „Professional Edition“, die durch eine kleine jährliche Gebühr alle schnellen Bug fixes und alle Features freischaltet.
Man benötigt zum Betrieb vom Observium eine klassische LAMP (Linux, Apache, MySQL, PHP) Umgebung mit den üblichen Verdächtigen (fping, Net-SNMP, RRDtool, Graphviz). Schnellste Ergebnisse erzielt man mit Debian bzw. Ubuntu oder RHEL bzw. Centos.
Als Abfragesprache nutzt Observium für (fast) alles SNMP. Es gibt noch zusätzlich einen UNIX-Agenten, der auf allen gängigen Unixen nach dem check_mk Rückgabeschema funktioniert. Dieser wird dazu verwendet um Werte, welche nicht oder nur schwer per SNMP zu bekommen sind, darzustellen.
02: Was ist so richtig toll an Observium?
- Performant
Leider ist bei vielen kommerziellen NMS nicht selbstverständlich, dass man nicht nach einem Query mal Kaffee trinken gehen kann.
Observium hingegen ist sehr effizient und modular programmiert, schleppt keine programmiertechnischen „Altlasten“ mit sich rum und bietet dadurch sehr angenehme und gute Performance, sowohl im Datensammeln (aka „Pollen“) als auch in der Darstellung.
Sollte es doch zu Performanceengpässen kommen ist aufgrund der LAMP-Basis sehr schnell an der richtigen Stelle gedreht. - Einfach zu verwenden
Auch wenn unter der Haube sehr stark von SNMP Gebrauch gemacht wird, benötigt man bei Observium definitiv keine tiefergehenden SNMP Kenntnisse. Einzig und allein wie man eine SNMP-Community (V1, V2C, V3) mit etwaiger Authentifizierung anlegt, genügt.
Ein sehr angenehmes Feature ist, dass Observium über verschiedene Autodiscovery Mechanismen verfügt und somit gerade bei großen Netzwerken seine Stärken ausspielen kann. Autodiscovery bezieht seine Daten aus xDP (LLDP, CDP, …) BGP und OSPF Nachbarn.
Alle Informationen werden in einem übersichtlichen und zentralen Dashboard zusammengefasst. - Integration anderer Open Source Tools
Da Observium nicht den Anspruch hat, alles zu können und das Rad neu zu erfinden, bietet es die Integration folgender OpenSource Tools in die Observium Oberfläche an:- syslog-ng
Damit können alle Hosts zum zentralen Observium Server „sysloggen“ und die entsprechenden Einträge werden gut sortiert und durchsuchbar dargestellt. - rancid
Damit ist es möglich eine Konfigurationsverwaltung im Observium zu integrieren. Durch die Verwendung von CVS oder SVN im Hintergrund kann auch eine Konfigurationshistorie vorgehalten werden. - collectd
Durch collectd können beliebige Graphen (auch von remote Hosts) in Observium aufgenommen werden. Der Autor dieses Artikels verwendet diese Schnittstelle sogar um komplett „fremde“ Graphen in Observium darzustellen. - nfsen
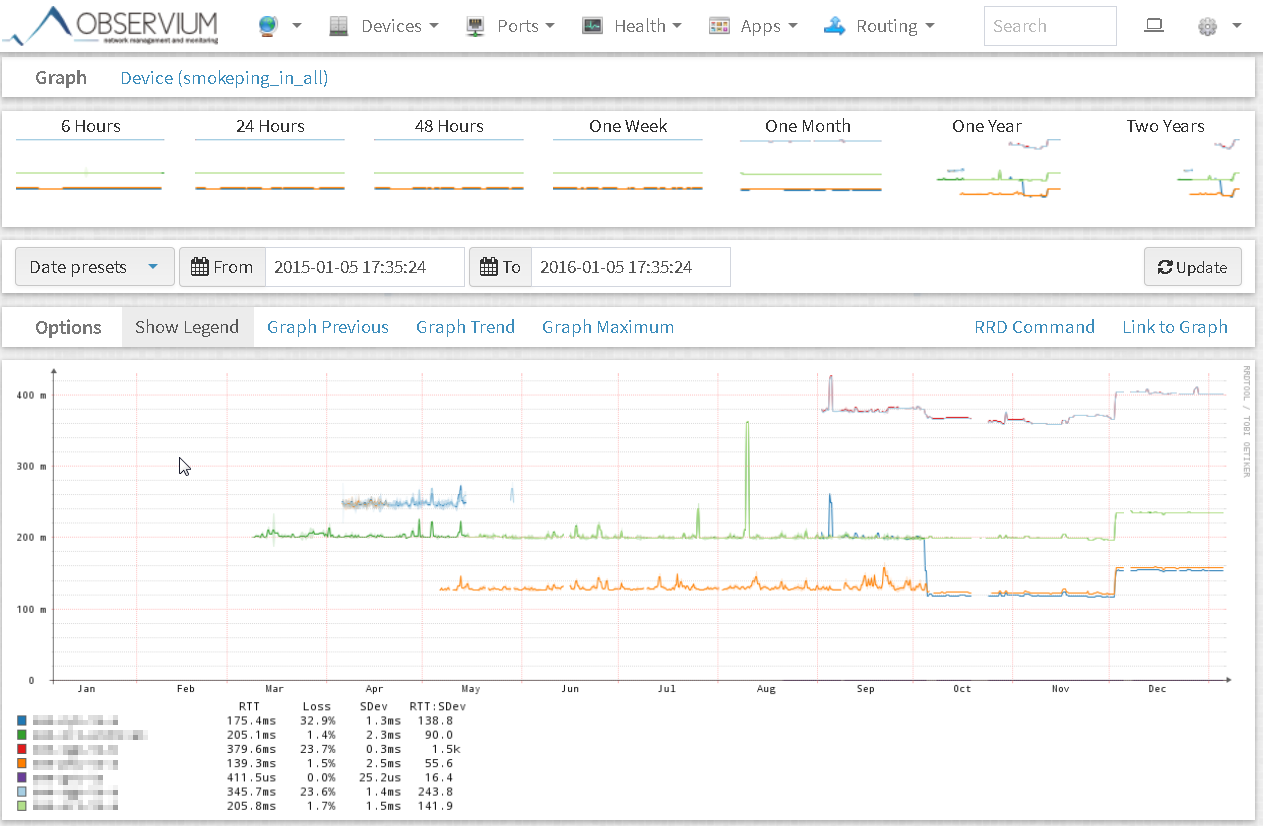
Damit können NetFlows eingesammelt und grafisch aufbereitet werden. - smokeping
Mit smokeping können zentral oder dezentral (Ping) Latenzen gemessen und dargestellt werden. Dies bietet sich an, wenn man nicht über Equipment verfügt, welches das SLA oder RPM beherrscht.
Eine Cisco SLA oder Juniper RPM Integration(ab R6686) ist in Observium enthalten. - PHP Weathermap
Auch die allseits beliebten PHP-Weathermaps können in Observium integriert werden. Dabei hilft es, dass Datenquellen für die Verbindungsdarstellung direkt über Observium herausgesucht werden können – langes „RRD-Suchen“ entfällt also.
- syslog-ng
- Ein agiles und dynamisches Entwicklerteam
Dass Observium ganz sicher nicht perfekt ist, wurde schon erwähnt. Daher ist es umso wichtiger, dass im Hintergrund ein Entwicklerteam steht, das zum einen Prinzipien hat und vertritt und zum anderen jedoch auch schnell und agil auf Kundenanforderungen reagiert.
Unsere Erfahrung mit dem Core-Team von Observium sind durchwegs positiv – kritische Bugs wurden bisher immer innerhalb von weniger als 48 Stunden repariert, größere Erweiterungen waren bisher innerhalb von Wochen – nachdem man sich einig war, was wirklich sinnvoll ist – integriert.
Hierbei ist anzumerken, dass entsprechende Entwicklungen von uns bezahlt werden mussten – von Luft und Liebe alleine kann niemand leben :-). - Alarmierungskonzept
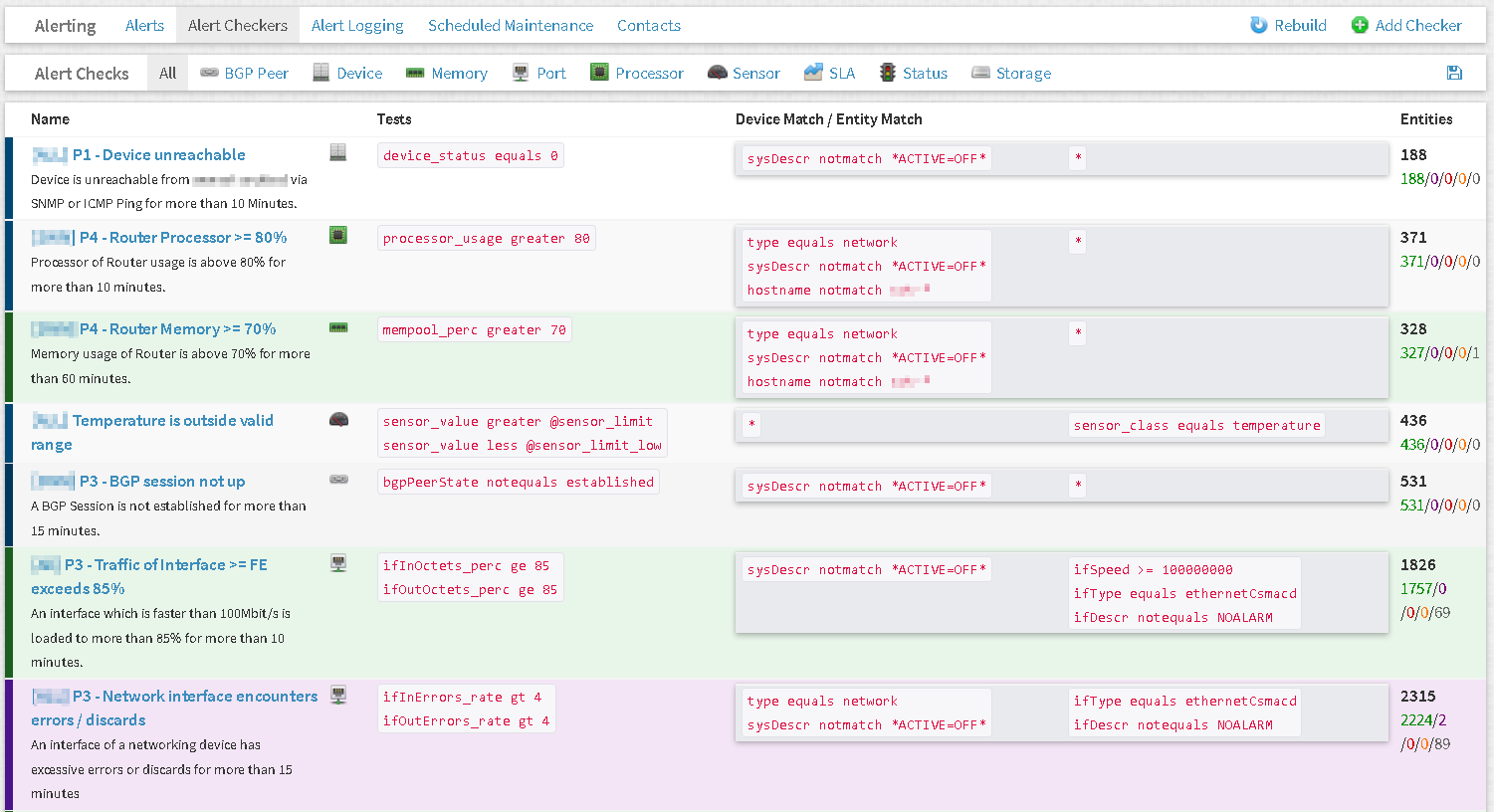
Wirklich „anders“ aber auch sehr schön ist das Alarmierungskonzept von Observium. Das Grundprinzip ist leicht beschrieben:- Es gibt sogenannte „Alert Checks“, welche man sich als Beschreibung oder Vorlage einer Fehlerklasse vorstellen kann.
- Diese „Alert Checks“ werden dann auf alle sogenannte „Entities“ (Gerät, Port, BGP-Session, Toner, SLA, …) angewendet und somit entstehen aus sehr wenigen „Alert Checks“ und den verwendeten Geräten sehr schnell viele „Alerts“, die quasi als Instanz eines Checks zu sehen sind.
- Kommen neue Geräte oder Geräteerweiterungen (z.B. Ports) hinzu, werden automatisch die „Alert Checks“ Regeln auf diese angewendet.
Somit gehört das Nachpflegen von Checks bzw. das Vergessen eben solchens der Vergangenheit an.
- Aufzeichnung und Visualisierung nahezu aller Daten
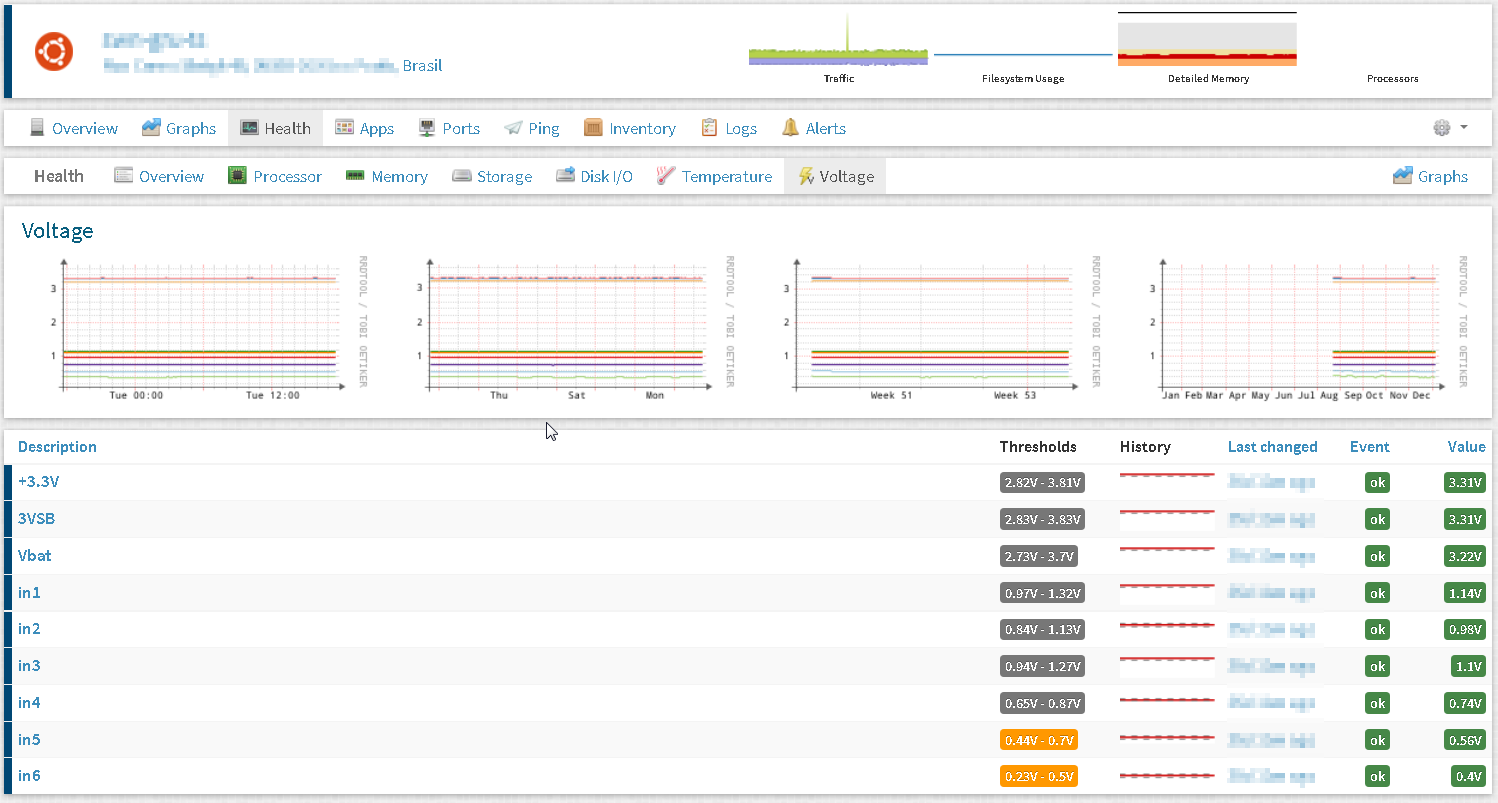
Da Observium grundsätzlich „erst mal alles“ mitprotokolliert und versucht in Graphen zu archivieren hat man eine sehr große Datenbasis, die man im Fehler oder Auditfalle zurate ziehen kann.
Beispielsweise hat sich beim Autor dieser Zeilen ein Tod eines Netzteils mit abfallenden Spannungswerten aus lm_sensors angekündigt und es konnte schon mal Ersatz besorgt werden, bevor das Netzteil wirklich defekt ging. Niemand kommt auf die Idee manuell präventiv alle Sensorwerte mit zu protokollieren. Somit wäre dieser Fehler ohne Observium wohl schwerwiegender gewesen.
Die folgenden Bilder geben die Inhalte dieses Absatzes visuell wieder:
-
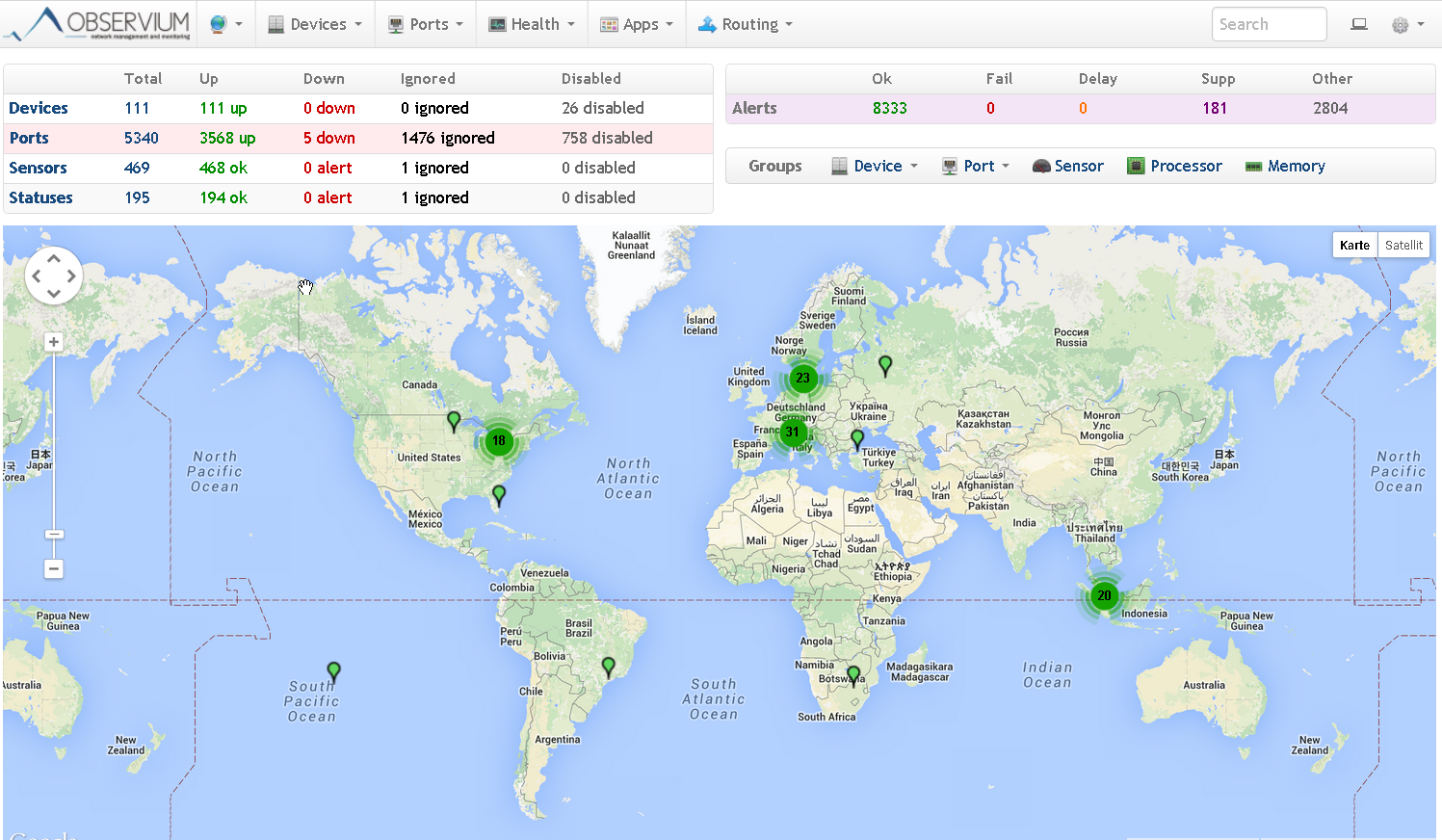
- Das Dashboard
-
- Alarmierungen – Konfiguration
-
- Details (z.B. Sensoren)
-
- Integration – Smokeping
-
- Integration – Collectd
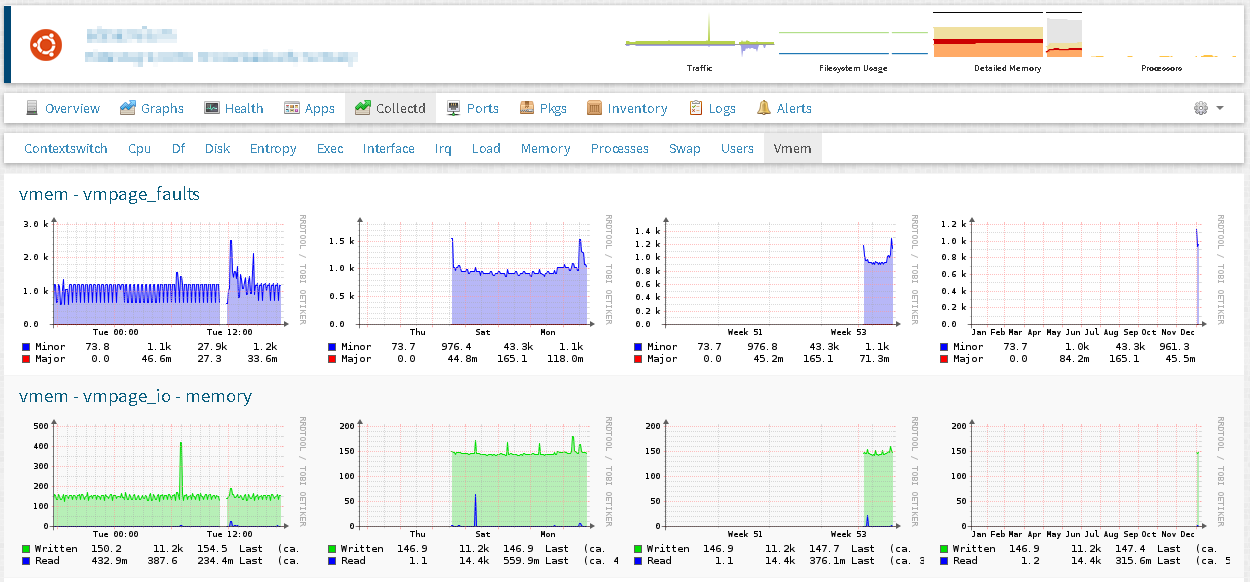
-
- Integration – Syslog
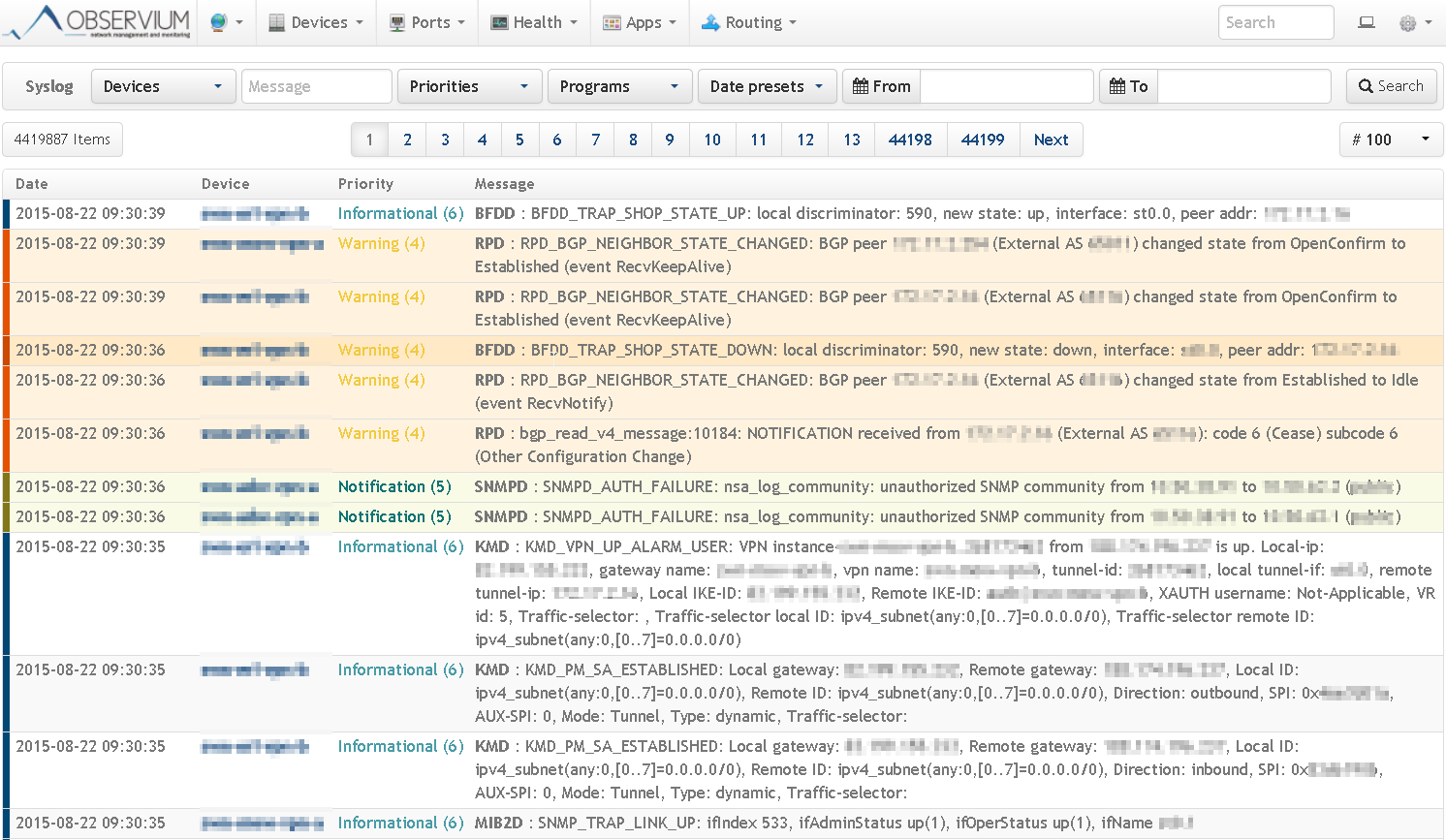
03: Unterschiede zu anderen NMS/Monitoring Lösungen
Observium ist definitiv kein System das stark an die Bedürfnisse angepasst werden kann oder muss. Das bedeutet, dass man entweder mit dem Featureset und Programmaufbau zufrieden ist oder man sollte besser ein anderes System verwenden.
Darin liegt die große Schwäche und Stärke zugleich: Es gibt sinnvolle Defaults, die Observium vom Start an benutzbar machen, allzu großes Customizing ist jedoch nicht möglich.
Auch das Alarmierungskonzept von Observium ist, wie oben vorgestellt, anders als bei den meisten anderen Systemen.
Leider mangelt es manchmal ein wenig an der Dokumentation. Konkret bedeutet es, dass einige Features einfach noch nicht dokumentiert sind – die Qualität der vorhandenen Dokumentation ist jedoch hervorragend!
04: Was macht teamix mit Observium / teamix Observium Best Practises
Wir bei teamix setzen Observium vor allem zur Überwachung unserer Managed-Services und SLA Kunden ein. Dazu bekommt jeder Kunde eine eigene Observium Instanz, auf welche er direkt zugreifen kann. Das schafft einen sehr hohen Transparenzgrad für uns und den Kunden, bei unseren Diensten.
Weiterhin koppeln wir mittels einer selbst entwickelten Schnittstelle (aka check_observium.pl, siehe unten) alle Kundeninstanzen an eine zentrale Nagiosinstanz (ist und bleibt das Schweizer Bastelmesser), welche unser Betriebs,- und Supportteam im Falle eines Fehlers alarmiert.
Durch diesen Einsatz von Observium haben wir folgende (manchmal triviale) Best Practises entwickelt:
1.) Es ist besser die Gerätekonfiguration anzupassen, als das NMS.
Wenn beispielsweise ein Alarm konfiguriert wurde auf Ports die Down sind, ist es besser die Ports im Switch/Router zu „disablen“ als dies einzeln in der Observium Konfiguration zu „klicken“.
Es ist auch sinnvoller den SNMP-Locaction String anzupassen, dass er von Google Maps in Koordinaten umgewandelt werden kann, als im Observium jedes mal „Override Location“ zu aktivieren.
Selbiges gilt für Interface Beschreibungen und andere Dinge.
2.) Benötigte Hardware
Die physikalische oder virtuelle Hardware eines Observium Servers ist durchaus durch die schiere Menge an Datenquellen und Graphen (RRDs) gefordert – daher sollte beim Sizing auf Folgendes geachtet werden. Unsere Erfahrungen haben wir zur Veranschaulichung mit Graphen eines 70 Devices/ 4000 Ports / 300 Sensors Observiums beigefügt, welcher auf einer ESX-Farm mit NetApp Storage (SATA+FlashCache) betrieben wird.
Sollte eine detailliertere Beratung und Informationen notwendig sein, bitte einfach bei uns melden (siehe unten).
- Vernünftiges I/O Subsystem
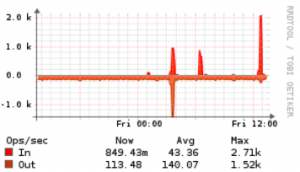 Es müssen nicht immer gleich massenhaft SSDs sein, aber man kann bei „normalen“ Observium Installationen durchaus mal einige tausend IO/s auf einem System haben. Wenn man Observium beispielsweise in einer virtualisierten Umgebung betreibt macht ein Flash basierter Cache (read-only oder read-write) definitiv Sinn.
Es müssen nicht immer gleich massenhaft SSDs sein, aber man kann bei „normalen“ Observium Installationen durchaus mal einige tausend IO/s auf einem System haben. Wenn man Observium beispielsweise in einer virtualisierten Umgebung betreibt macht ein Flash basierter Cache (read-only oder read-write) definitiv Sinn.
Eine weitere Möglichkeit das Thema IO in den Griff zu bekommen wäre – gerade bei kleineren Systemen – einen rrdcached zu verwenden. Eine genaue Anleitung wie man das am besten bewerkstelligt findet man hier.
- Mehr Cores mit wenig GHz sind besser als viele GHz und wenig Cores
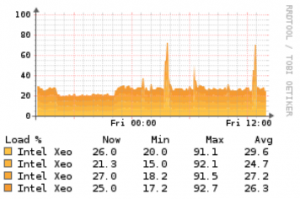 Da Observium seine Hauptarbeit im „Polling“ besitzt und dies glücklicherweise im Gegensatz zu anderen Monitoring Tools sehr gut parallelisierbar – man kann angeben wie viele Pollingthreads gleichzeitig laufen – ist, macht der Betrieb auf Mehrprozessorsystemen durchaus Sinn.
Da Observium seine Hauptarbeit im „Polling“ besitzt und dies glücklicherweise im Gegensatz zu anderen Monitoring Tools sehr gut parallelisierbar – man kann angeben wie viele Pollingthreads gleichzeitig laufen – ist, macht der Betrieb auf Mehrprozessorsystemen durchaus Sinn.
Im Graphen rechts sieht man auch sehr schön, dass sich die Last immer gleichmäßig über alle Cores verteilt.
- Anforderungen an Arbeitsspeicher
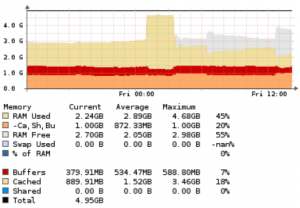 RAM kann man nie genug haben, das ist die altbekannte UNIX-Weisheit, aber Observium ist grundsätzlich nicht arbeitsspeicherhungrig.
RAM kann man nie genug haben, das ist die altbekannte UNIX-Weisheit, aber Observium ist grundsätzlich nicht arbeitsspeicherhungrig.
Wenn man jedoch viel und schnell Graphen anschauen möchte helfen einem natürlich die Filesystem Puffer des Betriebssystems durchaus schnellere Antwortzeiten zu bekommen. Grundsätzlich sollten jedoch nicht Unsummen in RAM investiert werden, da ist der gleiche Invest in ein SSD-Basiertes Storage Subsystem besser angelegt. Bei virtualisierten Observium Instanzen bietet sich an „mal“ mit 4GB zu starten und dann „zu schauen“ wie weit man kommt. Sollte der RAM nicht ausreichen kann man diesen ja probeweise nach oben drehen. Wichtig, gerade beim Arbeitsspeicher ist, das man nicht vergessen darf, dass Observium eine MySQL Datenbank im Hintergrund hat und hier ein entsprechendes MySQL Tuning auch in Betracht gezogen werden sollte – schließlich will man ja, dass der teure RAM auch verwendet wird.
3.) Der zentrale Observium Server kann gleich noch für weitere Aufgaben im Netzwerk genutzt werden:
- Zentraler Syslogserver
Die Syslogeinträge werden dann auch gleich im Observium dargestellt. - Zentraler „Archival“-Server
Dieser Punkt ist Juniper/JunOS spezifisch, da JunOS seine Konfigurationen beispielsweise per SCP ebenfalls wegsichern kann. Ist als Ergänzung und „doppelter Boden“ zum RANCID zu sehen. - Admin „Jumpstation“
Da die IP(s) vom Observium Server sowieso zur Administration freigegeben sein müssen (zumindest SNMP) kann dieser auch gleich zur Administration der LAN/WAN Infrastruktur verwendet werden.
05: Wie schaut es mit der Integration des teamix-Portfolios aus?
Da teamix in den jeweiligen Geschäftsbereichen eine „Single Vendor Strategie“ verfolgt, ist es natürlich sehr interessant und wichtig wie die einzelnen Hersteller/Technologien unterstützt werden. Einzelne Screenshots der jeweiligen Produktintegrationen wurden als Bildergalerie am Ende des Absatzes eingearbeitet.
- NetApp
- 7-Mode Systeme werden sehr gut unterstützt und man bekommt die wichtigsten Werte komfortabel geliefert.
- CDOT Systeme sind aktuell ein Schwachpunkt, da die SNMP-Implementierung von CDOT aktuell „suboptimal“ ist. Hier sind wir aber gerade in Planung dies mit dem Entwicklerteam von Observium zu verbessern.
- E-Series Systeme werden leider noch nicht unterstützt
- vSphere / ESXi
- Solange ein vCenter Host mit SNMP Zugriff existiert oder der ESX-Server noch SNMP Support hat existiert eine recht annehmbare Integration ins Observium.
- Auch einzelne ESX-Server können nach dem Aktivieren von SNMP ins Observium aufgenommen werden.
- Aruba Networks (now on behalf of HP)
- Die controllerbasierte Lösung von Aruba funktioniert tadellos und kann sowohl einzelne Access Points als auch den Gesamtzustand des WLANs sehr gut darstellen.
- Leider ist Aruba Instant (controllerlose Variante) noch sehr rudimentär implementiert.
- JunOS / Juniper
- Alle von uns verwendeten Produktfamilien (EX, MX, SRX, J, QFX Series) sind sehr gut integriert.
- Einzelne Dinge, die noch nicht abgebildet sind, werden von uns nach und nach bei den Entwicklern „eingekippt“.
- Bei Systemen mit sehr vielen Ports (z.B. Virtual Chassis oder Virtual Chassis Fabric) muss man aufpassen, dass die jeweilige CPU der Routing Engine in er Lage ist die SNMP-Anfragen für alle Interfaces zeitnah zu beantworten. Siehe hierzu auch unseren Blog-Artikel zu diesem Thema.
- CISCO
- Cisco im Netzwerkumfeld ist perfekt und allumfassend integriert, da Observium ursprünglich mit CISCO Support begonnen hat und viele der Entwickler auch aus dem CISCO Universum kommen.
- Eaton USVs
- Alle Eaton USVs sind sehr gut in Observium integriert.
- Brocade
- Die von uns verwendeten Brocade Switches (ausschließlich FibreChannel) sind gut integriert.
- Nagios
- Bis dato gab es keine Nagios-Schnittstelle zu Observium, darum haben wir selbst Hand angelegt und ebendiese entwickelt (siehe auch andere Stellen in diesem Artikel).
06: Welche Dienstleistungen und Erweiterungen bietet teamix rund um Observium an?
- Bezug der Observium Lizenzen über uns
Dies ist gerade für Unternehmen und Institutionen interessant, welche nicht mal so einfach „im Internet“ oder „per Kreditkarte“ bestellen dürfen bzw. können.
Bei uns gibt es eine deutsche Rechnung mit deutscher Umsatzsteuer und EUR. 🙂
Unsere Preise sind identisch zu den Preisen von observium.org. - Beratung, Installation, Support und Betrieb von Observium
Wir können jede Phase eines Observium Projekts unterstützen oder durchführen. Ergänzend hierzu können wir neue Featureideen und Bugreports mit dem Entwicklerteam abstimmen und eine Implementierung entsprechend einsteuern. - Bereitstellen einer Nagios-Schnittstelle (check_observium)
Mit check_observium können ein oder mehrere Observium Instanzen in ein zentrales Nagios Monitoring System übernommen werden. Dabei macht man sich das sogenannte Ampelprinzip zunutze.
Das bedeutet, dass man seine Alerts wie gewohnt im Observium definieren kann und dann für jedes Objekt-Klasse (Observium Speak Entity) eine Ampel (Grün, Orange, Rot) bekommt und somit nicht für jeden neuen Alert am Nagios basteln muss.
Meldet eine Objekt-Klasse einen Fehler (z.B. „Es gibt einen Alert, der mit Ports zu tun hat“) wird man vom Nagios benachrichtigt und kann im entsprechenden Observium (mehrere Instanzen) nachschauen was genau los ist.
Das Plugin unterstützt neben der Alarmierung natürlich auch eine Erholung der entsprechenden Alerts. - Inventarisierungsschnittstelle für Juniper/JunOS Service Renewals (get_junos_inventory)
Gerade wenn es darum geht schnell herauszufinden ob noch alle Geräte im Service sind ist eine gut gepflegte Inventardatenbank ein Segen. Observium besitzt ebensolche, nur der Zugriff auf die für die Serviceüberprüfung notwendigen Geräteseriennummern gestaltet sich nicht immer als einfach (eigentlich nur virtual Chassis).
Das Tool „get_junos_inventory“ holt alle relevanten Informationen (incl. Adressdaten) aus dem Observium und ermöglicht so eine Serviceabfrage in wenigen Sekunden.
07: Dank Schlusswort
Dank geht hier ganz besonders an meine Frau Christiane, die mir während meines Urlaubs erlaubt hat diesen Artikel zu schreiben.
Ansonsten geht mein Dank an meinen (Ex)Kollegen Felix, der mich auf Observium aufmerksam gemacht hat und natürlich an unsere Kunden mit denen wir bereits erfolgreiche Projekte mit Observium realisiert haben und auch als Referenz nennen dürfen:
- Sivantos – The Hearing Company
- Kraftanlagen München
- Elaxy Solutions
- u.v.m.
Sollten also Fragen bestehen oder eine Live-Demo in einer größeren Umgebung benötigt werden, dann bitte direkt und vertrauensvoll über die bekannten Kanäle an uns wenden.
Sie können uns auch auf der it-sa 2016 in Nürnberg vom 18.-20. Oktober 2016 an Stand 12.0-210 kennenlernen.
Richard Müller

Richard Müller ist Geschäftsführer der Proact Deutschland GmbH. Den "kreativen" Umgang mit Computern und Datennetzen lernte er schon im Schulalter. Bis heute hat Richard eine Begeisterung für technisch brilliante Konzepte und Lösungsansätze in den Bereichen IT-Infrastruktur - hier vor allem alles rund ums Netzwerk.



