Mein letzter Artikel über Neuigkeiten beim Elastic Stack ist schon zwei Jahre alt. Gerade angesichts der enormen Geschwindigkeit, die die Entwickler des Elastic Stack an den Tag legen, ist dies ein guter Anlass, über wesentliche Neuerungen im Elastic Stack 6.6 zu berichten. Dieser Artikel stellt nur eine Auswahl der großen neuen Funktionen dar, da es seit dem Elastic Stack 5.2 sehr viele Neuerungen gibt.
X-Pack gleich mit dabei
Bislang war es erforderlich, das proprietäre X-Pack auf allen Hosts eines Elastic Stack zu installieren, um alle Vorteile zu nutzen zu können. Da X-Pack aber als Plugin daher kam, verkomplizierte das auch Aktualisierungen des kompletten Stacks.
Ab Elastic Stack 6.3 ist das X-Pack gleich mit dabei. Oben drauf gibt es noch eine kostenlose Basis-Lizenz. Es entfällt, eine solche Lizenz extra anzufordern und jährlich zu erneuern. Die Hintergründe zur Entscheidung, X-Pack teilweise zu öffnen, erläutert der Blog-Artikel Doubling Down on Open von Shay Banon. Der Blog-Artikel beschreibt offen die Herausforderung kommerzielle Interessen mit dem Gedanken freier Software in Einklang zu bringen.
X-Pack bietet eine ganze Reihe von Zusatz-Funktionen, von denen sich eine ganze Reihe auch mit der Basis-Lizenz nutzen lässt.
In weiteren 6.x-Versionen nach 6.3 kamen so viele weitere Funktionen dazu, die sich mit der Basis-Lizenz zumindest teilweise nutzen lassen, dass das seitliche Menü mitunter nicht mehr ganz auf eine Browser-Seite passt.
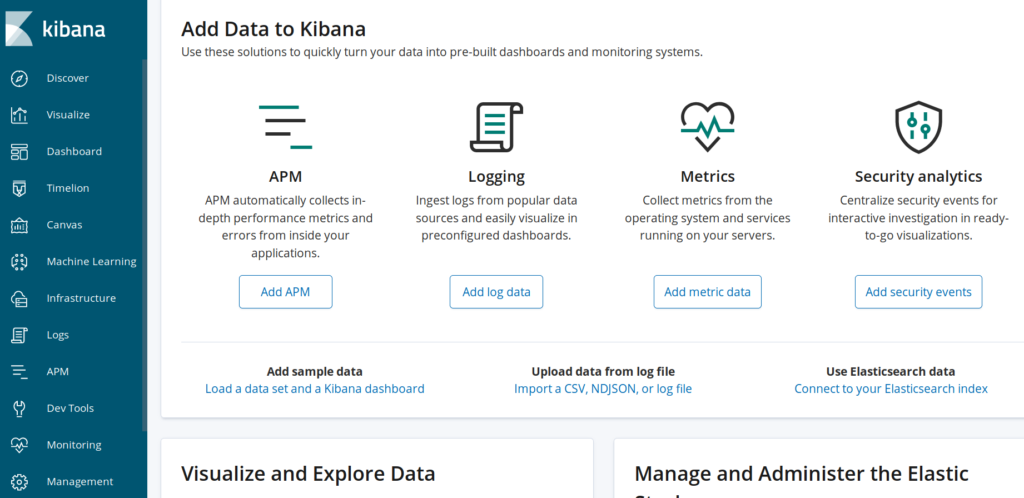
Elastic Stack Monitoring
Eine dieser Funktionen ist ein grundlegendes Monitoring aller verwendeten Komponenten des Elastic Stacks. Ein Dashboard informiert den Admin auf einen Blick über den Zustand vom Elasticsearch Cluster sowie von den Kibana-, Logstash- und Beat-Instanzen. Bei Bedarf offenbaren wenige Klicks weitere Details, inklusive Graphen zu wesentlichen Performance-Aspekten.
Grok Debugger
Eine weitere Funktion aus der Basis-Lizenz ist der Grok Debugger im Kibana unter Dev Tools. Bei der Analyse von Protokoll-Daten aus Anwendungen, für die es bislang keine Grok-Muster gibt, unterstützt der Grok Debugger beim Entwickeln der passenden Muster. Grok Debugger gibt es auch im Internet, aber durch den nun lokal verfügbaren Debugger, ist es nicht erforderlich, Beispiel-Daten auf einer fremden Webseite einzufügen.
Spaces
Zudem bietet Kibana noch eine weitere praktische Funktion: Mit Spaces lassen sich voneinander getrennte Ansichten von Kibana definieren. In jeder Ansicht sind dann nur die Dashboards, Suchen und anderen Kibana-Objekte sichtbar, die dieser Ansicht zugeordnet wurden . So kann jede Abteilung quasi ihr eigenes Kibana konfigurieren. Anders als beim Community-Plugin Own Home, kommen dabei jedoch keine eigenen Kibana-Indizes zum Einsatz. Kommt die kostenpflichtige Benutzerverwaltung zum Einsatz, lassen sich bestimmte Spaces auch nur für bestimmte Benutzer freigeben.
Index Lifecycle Management
Eine für die Performance eines Elasticsearch-Cluster wichtige Größe ist die Anzahl der Shards. Ein Shard ist eine einzelne Lucene-Suchmaschine, die immer auf einem Knoten des Clusters läuft. Bei zu wenigen für einen Index, kann Elasticsearch einerseits diesen nicht entsprechend auf mehreren Knoten verteilen. Andererseits jedoch verbrauchen Shards auch Resourcen wie Datei-Handles, Hauptspeicher, CPU-Zyklen. Einerseits kann Elasticsearch eine Such-Anfrage bei mehreren Shards auf mehrere Knoten aufteilen. Andererseits ist es aufwendig das Ergebnis der Anfrage aus mehreren Teil-Ergebnissen zusammenzufügen. So erwähnt der Blog-Artikel „How many shards should I have in my Elasticsearch cluster?“ von Christian Dahlqvist Shard-Größen für zeit-basierte Daten Shard-Größen von 20 bis 40 GiB. Ab Elasticsearch 7 gibt es zudem ein konfigurierbares weiches Limit von 1000 Shards pro Knoten.
Logstash, Beats und Fluentd mit aktivierter Logstash-Kompatibilität legten bislang jedoch einen Index pro Tag an. Das ergibt bei wenigen Hosts mitunter nicht mal ein 1 GiB an Daten pro Tag. Wer alte Indizes, z.B. mit Curator, erst ein halbes Jahr später löscht, stößt so einerseits an dieses weiche Limit und hat mitunter mit reduzierter Performance zu tun.
Hier kommt Index Lifecycle Management ins Spiel. Kurz beschrieben bedeutet es: Elasticsearch verwaltet die Index-Größen selbständig. Dazu lässt sich für einen Index eine Richtlinie hinterlegen, die z.B. besagt:
- Rollover nach 30 Tagen oder 50 GiB.
- Lösche alte Indizes nach 180 Tagen.
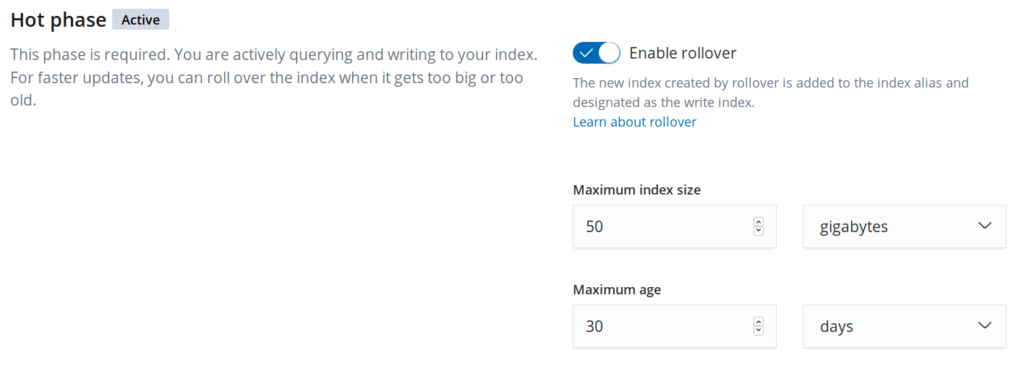
Dabei unterscheidet Elasticsearch vier Phasen von denen alle außer der heißen Phase optional sind:
- Hot Phase: Aktives Schreiben und Abfragen des Indexes.
- Warm Phase: Abfragen auf den Index, jedoch keine Schreibvorgänge mehr. Der Index ist nur lesbar. Kann auf langsamerer Hardware liegen.
- Cold Phase: Nur noch seltene Abfragen. Kann auf deutlich langsamerer Hardware liegen und weniger Replika haben.
- Delete Phase: Löschen.
In Elastic 6.6 unterstützen Elasticsearch, die Beats und Logstash dieses Vorgehen. So legt das Elasticsearch-Ausgabe-Plugin für Logstash mit der Option ilm_enabled keine täglichen Indizes mehr an. Das ILM ist derzeit noch experimentiell. Die genaue Funktions- und Konfigurationsweise kann sich noch ändern.
Rolling Upgrades
Nicht zuletzt erleichtert Elasticsearch ab Version 6.0.0 das Aktualisieren auf eine neue Major-Version. Bislang war dazu erforderlich, alle Nodes eines Clusters herunterzufahren, zu aktualisieren, und erst dann alle Nodes wieder zu starten. Nun gelingt diese Aktualiserung wie bei Minor-Updates durch ein Rolling Upgrade, bei dem sich die Nodes nacheinander aktualisieren lassen, ohne das eine Downtime des Clusters entsteht.
Zudem gibt es mittlerweile einen Assistenten für die Aktualisierung auf Elasticsearch 7.0, der vor möglichen Problemen wie z.B. dem weichen Limit für Shards warnt und zusätzlich die passenden Links zur Dokumentation der Abhilfe anbietet.
Ausblick Elastic 7.0
Darüberhinaus arbeitet das Elastic-Team fleißig an der Version 7 des Stacks mit interessanten Neuerungen wie einer mitunter deutlich erhöhten Abfrage-Performance für die ersten N Treffer einer Suche in Elasticsearch oder standardmäßigen Autovervollständigung von Abfragen in Kibana. Die Version 7.0-beta1 ist bereits fertig. Stay tuned…
Welches Thema interessiert Sie am meisten?
Welches Thema rund um die Logfile-Analyse oder auch zu Linux im Allgemeinen interessiert Sie am meisten? Welches Thema würden Sie gerne im Blog sehen? Schreiben Sie uns.
Gerne beantworten wir Ihre Fragen. Unsere Logfile-Analyse-Schulung bei qSkills gibt einen Überblick über die gängigen Werkzeuge zur Logfile-Analyse. Durch das Installieren und Konfigurieren der gängigen Lösungen erhält jeder Teilnehmer Hands On-Erfahrungen mit den einzelnen Lösungen. Der Nächste Termin findet vom 6.5.2019 bis 9.5.2019 statt.
Martin Steigerwald

Martin Steigerwald beschäftigt sich seit Mitte der 90er Jahre mit Linux. Er ist langjähriger Autor von Artikeln für verschiedene Computer-Magazine wie die LinuxUser (linuxuser.de) und das Linux-Magazin (linux-magazin.de). Seit Herbst 2004 ist er als Trainer für Linux-Themen bei Proact Deutschland in Nürnberg tätig.



