NetApp’s Clustered ONTAP ist inzwischen schon seit knapp 5 Jahren verfügbar, aber trotzdem fühlen sich auch routinierte 7-Mode Administratoren beim Umstieg auf cDOT von der neuen Kommandozeile meist überrumpelt. Auch ich selbst entdecke immer wieder über die verschiedenen Releases hinweg, neue Raffinessen und Möglichkeiten der Clustershell.
Im Rahmen dieser 2-teiligen Blogreihe möchte ich die interessantesten Neuerungen und Funktionen aufzeigen, um damit allen Um- oder Neueinsteigern einen ersten Eindruck der CLI zu vermitteln.
Beginnen möchte ich mit einem Feature, das viele von uns bereits von anderen Kommandozeilen kennen und lieben: Tab Completion
Jedes Kommando kann in Clustered Data ONTAP durch das Drücken von „TAB“ um alle, für den Befehl möglichen Unterkommandos und Parameter, erweitert werden. Somit ist es ausreichend das gesuchte Grundkommando zu kennen – der Rest kann durch die Tab Completion ergänzt werden. Daher mein persönlicher Tipp: Einfach auf der Clustershell häufiger TAB drücken, damit wird das Prinzip und der extreme Vorteil sehr schnell deutlich.
Shortcuts
Eine weitere Funktion, die uns das Leben extrem vereinfacht: Shortcuts
|
1 2 3 4 |
cluster1::*> v Error: Ambiguous command. Possible matches include: volume vserver |
Anstatt jedes Kommando ganz ausschreiben zu müssen reicht es eine Abkürzung zu verwenden, solange diese eindeutig interpretiert werden kann. Anstatt „volume“ kann z.B. einfach die Abkürzung „vol“ verwendet werden. Falls die verwendete Abkürzung (wie in der Abbildung oben zu sehen) zu kurz bzw. mehrdeutig sein sollte, zeigt ONTAP alle möglichen Befehle an, die gemeint sein könnten.
Da auf der Clustershell alle Befehle in einer Art Verzeichnisstruktur aufgebaut sind, kann man durch die Shortcuts auch entsprechend schnell in die tieferliegende Befehlsstruktur einsteigen.
Ein Beispiel:
Um für eine SVM die DNS-Settings zu setzen, kann der Befehl:
|
1 |
cluster::> vserver services name-services dns |
oder abgekürzt auch einfach:
|
1 |
cluster::> dns |
verwenden werden.
Navigation innerhalb der Struktur – up/top
Schauen wir uns kurz den Aufbau der Clustershell etwas genauer an:
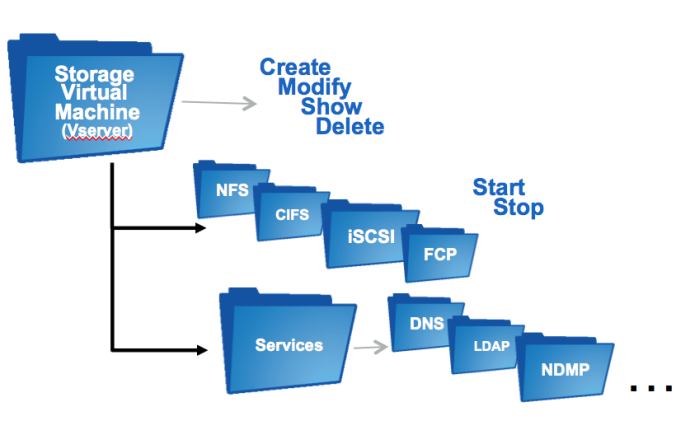
Die Anordnung der Kommandos ist (wie im Bild zu sehen) streng hierarchisch in Form einer Ordnerstruktur implementiert. Dadurch ergibt sich die Möglichkeit in den jeweiligen Ebenen zu navigieren, nämlich entweder nach unten oder nach oben. Auf Basis des oben aufgeführten Beispiels bedeutet das:
|
1 2 |
cluster::> dns cluster::vserver services name-services dns> |
Falls wir nun versehentlich eine Ebene zu weit nach unten gegangen sind und daher eine Stufe nach oben wollen, lautet die Lösung:
|
1 2 |
cluster::vserver services name-services dns> up cluster::vserver services name-services> |
Durch die Verwendung von „up“ landen wir wieder im übergeordneten Kontext und können ab hier wieder weiter navigieren.
Falls wir jedoch sofort und direkt in die oberste Ebene der CLI zurückkehren wollen, hilft uns der Befehl „top“:
|
1 2 |
cluster::vserver services name-services dns> top cluster::> |
Maximale Informationen – der Parameter „-instance“
Der Output vieler Kommandos ist in Clustered Data ONTAP auf ein übersichtliches Minimum reduziert. Das ist für einen ersten Überblick zwar absolut sinnvoll, reicht aber oft nicht aus um erweiterte Einstellungen und Settings zu kontrollieren.
Nehmen wir als Beispiel das Kommando „vol show“:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
cluster::> vol show Vserver Volume Aggregate State Type Size Available Used% --------- ------------ ------------ ---------- ---- ---------- ---------- ----- cluster1-01 vol0 aggr0_cluster1_01 online RW 44.82GB 36.88GB 17% cluster1-02 vol0 aggr0_cluster1_02 online RW 44.82GB 36.62GB 18% svm1 eng_users aggr1_cluster1_01 online RW 10GB 9.50GB 5% svm1 engineering aggr1_cluster1_01 online RW 10GB 9.50GB 5% svm1 svm1_root aggr1_cluster1_01 online RW 20MB 18.60MB 7% svmluns linluns aggr1_cluster1_01 online RW 10.31GB 10.18GB 1% svmluns svmluns_root aggr1_cluster1_01 online RW 20MB 18.73MB 6% svmluns winluns aggr1_cluster1_01 online RW 10.31GB 10.28GB 0% 8 entries were displayed. |
Möchte man sich nun die konkreten Einstellungen eines einzelnen Volumes im Detail ansehen, kommt der Parameter „-instance“ zum Einsatz:
vol show -volume eng_users -instance
Vorab kurz eine Warnung: Der Output wird EXTREM ausführlich!
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 |
cluster1::> vol show -volume eng_users -instance Vserver Name: svm1 Volume Name: eng_users Aggregate Name: aggr1_cluster1_01 List of Aggregates for FlexGroup Constituents: - Volume Size: 10GB Volume Data Set ID: 1027 Volume Master Data Set ID: 2147692844 Volume State: online Volume Style: flex Extended Volume Style: flexvol Is Cluster-Mode Volume: true Is Constituent Volume: false Export Policy: default User ID: - Group ID: - Security Style: ntfs UNIX Permissions: ------------ Junction Path: /engineering/users Junction Path Source: RW_volume Junction Active: true Junction Parent Volume: engineering Comment: Available Size: 9.50GB Filesystem Size: 10GB Total User-Visible Size: 9.50GB Used Size: 352KB Used Percentage: 5% Volume Nearly Full Threshold Percent: 95% Volume Full Threshold Percent: 98% Maximum Autosize (for flexvols only): 12GB Minimum Autosize: 10GB Autosize Grow Threshold Percentage: 85% Autosize Shrink Threshold Percentage: 50% Autosize Mode: off Total Files (for user-visible data): 311287 Files Used (for user-visible data): 102 Space Guarantee in Effect: true Space SLO in Effect: true Space SLO: none Space Guarantee Style: none Fractional Reserve: 0% Volume Type: RW Snapshot Directory Access Enabled: true Space Reserved for Snapshot Copies: 5% Snapshot Reserve Used: 0% Snapshot Policy: default Creation Time: Wed Oct 19 19:17:42 2016 Language: C.UTF-8 Clone Volume: false Node name: cluster1-01 Clone Parent Vserver Name: - FlexClone Parent Volume: - NVFAIL Option: off Volume's NVFAIL State: false Force NVFAIL on MetroCluster Switchover: off Is File System Size Fixed: false (DEPRECATED)-Extent Option: off Reserved Space for Overwrites: 0B Primary Space Management Strategy: volume_grow Read Reallocation Option: off Naming Scheme for Automatic Snapshot Copies: create_time Inconsistency in the File System: false Is Volume Quiesced (On-Disk): false Is Volume Quiesced (In-Memory): false Volume Contains Shared or Compressed Data: false Space Saved by Storage Efficiency: 0B Percentage Saved by Storage Efficiency: 0% Space Saved by Deduplication: 0B Percentage Saved by Deduplication: 0% Space Shared by Deduplication: 0B Space Saved by Compression: 0B Percentage Space Saved by Compression: 0% Volume Size Used by Snapshot Copies: 404KB Block Type: 64-bit Is Volume Moving: false Flash Pool Caching Eligibility: read-write Flash Pool Write Caching Ineligibility Reason: - Managed By Storage Service: - Create Namespace Mirror Constituents For SnapDiff Use: - Constituent Volume Role: - QoS Policy Group Name: - Caching Policy Name: - Is Volume Move in Cutover Phase: false Number of Snapshot Copies in the Volume: 3 VBN_BAD may be present in the active filesystem: false Is Volume on a hybrid aggregate: false Total Physical Used Size: 756KB Physical Used Percentage: 0% List of Nodes: - Is Volume a FlexGroup: false SnapLock Type: non-snaplock Vserver DR Protection: - |
„-instance“ gilt natürlich nicht nur als möglicher Befehlsparameter für „volume show“, sondern kann in allen erdenklichen CLI-Kommandos angewendet werden um den maximal ausführlichen Output als Ergebnis zu erhalten.
Ordnung für das Chaos – „-fields“
Zugegeben: Der Output den wir bei der Verwendung von „-instance“ erhalten oft ist extrem viel und daher auch manchmal wieder zu viel des Guten. Gibt es also eine Möglichkeit die Übersichtlichkeit beizubehalten und trotzdem ausschließlich die gesuchten Informationen auszugeben?!
Genau an dieser Stelle kommt der Parameter „-fields“ in Spiel.
Nehmen wir direkt wieder unser letztes Beispiel auf, aber lassen dieses Mal ausschließlich die Werte des Volumes für „Used“, „Available“ sowie „Percent-Used“ ausgeben. Um das zu erreichen verwenden wir „-fields“:
vol show -volume eng_users -fields Used,Available,Percent-used
|
1 2 3 4 |
cluster::> vol show -volume eng_users -fields Used,Available,Percent-used vserver volume available used percent-used ------- --------- --------- ----- ------------ svm1 eng_users 9.50GB 348KB 5% |
Das ist extrem nützlich und deutlich leichter zu lesen als der Ouptut von „-instance“.
Ausschluss von Ergebnissen – „!“
Gleichzeitig bietet die CLI auch die Möglichkeit den Output eines Kommandos auf Basis von Kriterien zu filtern. Möchte man sich z.B. alle Disks eines Clusters ausgeben lassen, die KEINE Spare-Disks sind, ist das folgende Kommando ein möglicher Ansatz:
disk show -state !Spare
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 |
cluster::> disk show -state !Spare Usable Disk Container Container Disk Size Shelf Bay Type Type Name Owner ---------------- ---------- ----- --- ------- ----------- --------- -------- Info: This cluster has partitioned disks. To get a complete list of spare disk capacity use "storage aggregate show-spare-disks". VMw-1.25 28.44GB - 0 VMDISK shared aggr0_cluster1_02, aggr1_cluster1_02 cluster1-02 VMw-1.26 28.44GB - 1 VMDISK shared aggr0_cluster1_02, aggr1_cluster1_02 cluster1-02 VMw-1.27 28.44GB - 2 VMDISK shared aggr0_cluster1_02, aggr1_cluster1_02 cluster1-02 VMw-1.28 28.44GB - 3 VMDISK shared aggr0_cluster1_02, aggr1_cluster1_02 cluster1-02 VMw-1.29 28.44GB - 4 VMDISK shared aggr0_cluster1_02, aggr1_cluster1_02 cluster1-02 VMw-1.30 28.44GB - 5 VMDISK shared aggr0_cluster1_02 cluster1-02 VMw-1.31 28.44GB - 6 VMDISK shared aggr0_cluster1_02 cluster1-02 VMw-1.32 28.44GB - 8 VMDISK shared aggr0_cluster1_02 cluster1-02 VMw-1.33 28.44GB - 9 VMDISK shared aggr0_cluster1_02 cluster1-02 VMw-1.34 28.44GB - 10 VMDISK shared aggr0_cluster1_02 cluster1-02 VMw-1.35 28.44GB - 11 VMDISK shared - cluster1-02 VMw-1.36 28.44GB - 12 VMDISK shared - cluster1-02 VMw-1.37 28.44GB - 0 VMDISK shared aggr0_cluster1_01, aggr1_cluster1_01 cluster1-01 VMw-1.38 28.44GB - 1 VMDISK shared aggr0_cluster1_01, aggr1_cluster1_01 cluster1-01 VMw-1.39 28.44GB - 2 VMDISK shared aggr0_cluster1_01, aggr1_cluster1_01 cluster1-01 VMw-1.40 28.44GB - 3 VMDISK shared aggr0_cluster1_01, aggr1_cluster1_01 cluster1-01 VMw-1.41 28.44GB - 4 VMDISK shared aggr0_cluster1_01, aggr1_cluster1_01 cluster1-01 VMw-1.42 28.44GB - 5 VMDISK shared aggr0_cluster1_01 cluster1-01 VMw-1.43 28.44GB - 6 VMDISK shared aggr0_cluster1_01 cluster1-01 VMw-1.44 28.44GB - 8 VMDISK shared aggr0_cluster1_01 cluster1-01 VMw-1.45 28.44GB - 9 VMDISK shared aggr0_cluster1_01 cluster1-01 VMw-1.46 28.44GB - 10 VMDISK shared aggr0_cluster1_01 cluster1-01 VMw-1.47 28.44GB - 11 VMDISK shared - cluster1-01 VMw-1.48 28.44GB - 12 VMDISK shared - cluster1-01 24 entries were displayed. |
Noch eine zusätzliche Besonderheit: Standardmäßig gibt die CLI immer nur die ersten 24 Ergebnisse (Zeilen) aus. Falls die Auflistung größer ist, muss hierfür die Leertaste gedrückt werden um die nächsten 24 Ergebnisse angezeigt zu bekommen.
Wer diesen Default-Wert anpassen möchte, damit z.B. immer sämtliche Ergebnisse auf einmal ausgegeben werden, kann das über den Befehl „rows“ ermöglichen.
|
1 |
cluster::> rows 0 |
„0“ bedeutet dass immer sofort sämtliche Ergebnisse des Kommandos ausgegeben werden. Natürlich lässt sich nun über einen sinnvollen Wert streiten, jedoch ist das im Endeffekt Geschmackssache und von der Systemgröße abhängig.
Do it again – „History“ und „Redo“
Zum Schluss dieses ersten Teils möchte ich noch auf das Kommando „history“ eingehen. Während der Arbeit auf der CLI kommt es ja immer wieder mal vor, dass man die gleichen Befehle zeitlich versetzt wiederholt um z.B. den Status eines laufenden Jobs zu überprüfen oder einfach weil man den gleichen Befehl für ein anderes Volume anwenden will. Während man dazu im 7-Mode eigentlich gezwungen war, den jeweiligen Befehl nochmal komplett neu zu tippen, macht uns die Clustershell hier das Leben leicht.
History
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
cluster::> history 1 rows 2 rows 0 3 rows 24 4 vol show 5 vserver 6 up 7 vserver 8 .. 9 man job 10 man rows 11 man top 12 vserver 13 top 14 man man 15 man redo 16 history 17 storage 18 .. 19 history |
Das Kommando „history“ zeigt die letzten abgesetzten Kommandos und in Kombination mit dem Befehl „redo“ lassen sich die jeweiligen Befehlszeilen sofort wiederholen.
„redo 4“ führt beispielsweise zur Wiederholung des Befehls „vol show“:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
cluster::> redo 4 Vserver Volume Aggregate State Type Size Available Used% --------- ------------ ------------ ---------- ---- ---------- ---------- ----- cluster1-01 vol0 aggr0_cluster1_01 online RW 44.82GB 36.72GB 18% cluster1-02 vol0 aggr0_cluster1_02 online RW 44.82GB 36.52GB 18% svm1 eng_users aggr1_cluster1_01 online RW 10GB 9.50GB 5% svm1 engineering aggr1_cluster1_01 online RW 10GB 9.50GB 5% svm1 svm1_root aggr1_cluster1_01 online RW 20MB 18.67MB 6% svmluns linluns aggr1_cluster1_01 online RW 10.31GB 10.18GB 1% svmluns svmluns_root aggr1_cluster1_01 online RW 20MB 18.63MB 6% svmluns winluns aggr1_cluster1_01 online RW 10.31GB 10.28GB 0% 8 entries were displayed. |
Bei einer so kurzen Befehlszeile ist das natürlich noch nicht so effektiv, aber umso länger das ausgeführte Kommando war, umso dankbarer ist man für „history“ und „redo“.
To be continued…
Im zweiten Teil der Serie werden wir uns weiterführenden Funktionen, wie z.B. der Verwendung von Wildcards, if- oder auch either-or-Statements widmen. Es gibt also noch einiges an Werkzeugen und Funktionen, die die Clustershell bereithält.
Wer sich die CLI und generell die Gesamtarchitektur von Clustered Data ONTAP genauer ansehen möchte, findet auch bei unserem Schulungspartner qSkills z.B. im Rahmen des Workshops ST200c das optimale Training.
Sprechen Sie uns einfach an – wir freuen uns immer über eine Nachricht oder generelles Feedback!
Stefan Bast

Stefan Bast ist seit Januar 2012 für Proact Deutschland tätig. Sein Schwerpunkt liegt auf den Technologien von VMware und NetApp. Außerdem richtet sich sein Fokus auf die ergänzenden Datacenter- und Cloud-Security Lösungen von Trend Micro, wie z.B. Deep Security oder ServerProtect. Neben den Tätigkeiten im Consulting ist er auch als Trainer im VMware Umfeld aktiv.



