Nachdem Benjamin Ulsamer in seinem letzten Blogpost bereits auf die Neuerungen in VMware Virtual SAN 6.5 eingegangen ist, wollen wir Euch auch die wichtigsten Neuerungen in VMware vSphere 6.5 bereitstellen. In Teil 2 der Reihe dreht sich alles um die Neuerungen im Bereich des ESXi Host Managements. VMware stellt durch das Update auf Version 6.5 zudem auch viele Neuerungen im Bereich vSphere HA, FT und DRS bereit.
1 Proactive HA
Proactive HA erkennt die Hardware-Bedingungen eines Hosts und ermöglicht es VMs zu evakuieren, bevor das Problem einen Ausfall verursacht. In Verbindung mit den beteiligten Hardwareherstellern wird das vCenter in die Hardwareüberwachungslösung integriert um den Status der überwachten Komponenten wie Lüfter, Speicher und Stromversorgungen zu empfangen. vSphere kann dann entsprechend dem möglichen Fehler konfiguriert werden. Sobald eine Komponente durch das Hardware-Monitoring-System als ungesund gekennzeichnet ist, wird vSphere den Host als mäßig oder stark verschlechtert, je nachdem, welche Komponente ausgefallen ist, klassifizieren. vSphere platziert den betroffenen Host in einen neuen Zustand namens Quarantäne-Modus. In diesem Modus verwendet DRS den Host nicht für Platzierungsentscheidungen für neue VMs, es sei denn, eine DRS-Regel könnte ansonsten nicht erfüllt werden. Zusätzlich wird DRS versuchen den Host zu evakuieren, solange dies keine Leistungsprobleme verursachen würde. Proaktives HA kann auch so konfiguriert werden, dass degradierte Hosts in den Wartungsmodus versetzt werden, der ein vMotion aller laufenden Maschinen als Folge hat.

2 vSphere HA Orchestrated Restart
vSphere 6.5 ermöglicht nun das Erstellen von Abhängigkeitsketten über VM-to-VM-Regeln. Diese Abhängigkeitsregeln werden erzwungen, wenn wenn vSphere HA verwendet wird um VMs von fehlgeschlagenen Hosts neu zu starten. Dies ist ideal für Multi-Tier-Anwendungen, die nicht erfolgreich starten, wenn sie nicht in einer bestimmten Reihenfolge neu gestartet werden. Ein übliches Beispiel hierfür sind ein Datenbank-, App- und Webserver. Im folgenden Beispiel werden VM4 und VM5 zur gleichen Zeit neu gestartet, da deren Abhängigkeitsregeln erfüllt sind. VM7 wird auf VM5 warten, da es eine Regel zwischen VM5 und VM7 gibt. Es müssen explizite Regeln erstellt werden, die die Abhängigkeitskette definieren. Wenn diese letzte Regel weggelassen wurde, würde VM7 mit VM5 neu starten, da die Regel mit VM6 bereits erfüllt ist.
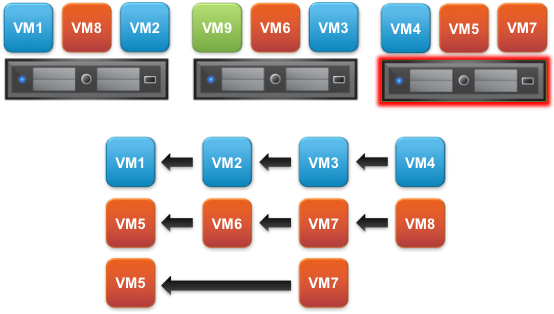
Zusätzlich zu den VM-Abhängigkeitsregeln fügt vSphere 6.5 zwei zusätzliche Neustartprioritätsebenen mit den Namen „Highest“ und „Lowest“ Wert hinzu, die fünf Gesamtzahlen bereitstellen. Dies bietet eine noch bessere Kontrolle bei Planung der Wiederherstellung von virtuellen Maschinen, die von vSphere HA verwaltet werden.
3 Simplified vSphere HA Admission Control
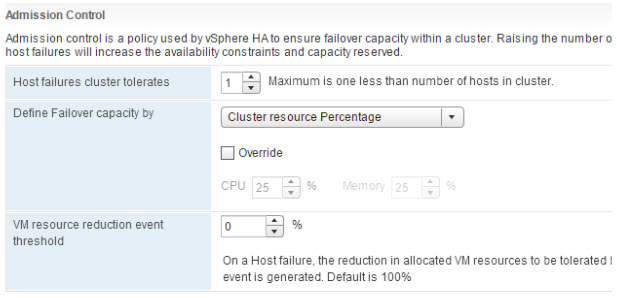
Mehrere Verbesserungen wurden an der vSphere HA Admission Control vorgenommen. Admission Control wird verwendet, um eine berechnete Menge an Ressourcen, die im Falle eines Host-Ausfalls verwendet werden, beiseite zu legen. Eine von drei verschiedenen Richtlinien wird verwendet, um die Menge der Kapazitäten zu bestimmen. In vSphere 6.5 wird diese Einstellung nun einfacher. Die erste große Änderung ist, dass der Administrator die Anzahl der zu tolerierenden Host-Ausfälle (FTT) definieren muss. Sobald die Anzahl der Hosts konfiguriert ist, berechnet vSphere HA automatisch einen Prozentsatz der Ressourcen, die beiseite gelegt werden sollen, indem die Regeln für die Admission Control „Prozentsatz der Clusterressourcen“ angewendet werden. Wenn Hosts hinzugefügt oder aus dem Cluster entfernt werden, wird der Prozentsatz automatisch neu berechnet. Dies ist die neue Standardkonfiguration. Allerdings ist es auch möglich die automatische Berechnung zu überschreiben oder eine andere Zulassungssteuerungsrichtlinie zu verwenden. Darüber hinaus gibt der vSphere Web Client eine Warnung aus, wenn vSphere HA feststellt, dass ein Host-Fehler eine Verringerung der VM-Leistung auf der Grundlage des tatsächlichen Ressourcenverbrauchs verursacht. Der Administrator kann konfigurieren, wie viel Leistungsverlust toleriert wird, bevor eine Warnung ausgegeben wird.
4 Fault Tolerance (FT)
Fault Tolernace in vSphere 6.5 integriert sich nun besser in DRS. Dies hilft dabei bessere Entscheidungen über Platzierung von VMs durch die Klassifizierung der Hosts auf der Grundlage der verfügbaren Netzwerkbandbreite zu treffen. Auch die auftretende Latenz wurde in diesem Release erheblich gesenkt. Dies öffnet nun die Tür für ein noch breiteres Spektrum geschäftskritischer Anwendungen. FT-Netzwerke können nun so konfiguriert werden, dass diese mehrere NICs verwenden, um die Gesamtbandbreite für den FT-Protokollierungsverkehr zu erhöhen. Dies ist eine ähnliche Konfiguration wie bei Multi-NIC vMotion, um zusätzliche Kommunikationskanäle für Umgebungen bereitzustellen, die mehr Bandbreite benötigten als eine einzelne NIC bereitstellen kann.
5 DRS Advanced Options
Drei bisher erweitere Einstellungen erhalten nun eine eigene Checkbox in der Benutzeroberfläche für eine einfachere Konfiguration:
- VM Distribution: Erzwingt eine gleichmäßige Verteilung von VMs. Dies wird dazu führen, dass DRS die Anzahl der VMs gleichmäßig über die Hosts verbreitet. Wenn DRS ein starkes Ungleichgewicht innerhalb der Leistungswerte der Hosts erkennt, wird es dieses durch vMotion von virtuellen Maschinen beheben.
- Memory Metric für Load Balancing: DRS verwendet Active Memory als primäre Metrik bei der Berechnung der Speicherbelastung eines Hosts. Der verbrauchte Speicher im Vergleich zum aktiven Speicher wird dazu führen, dass DRS die verbrauchte Speichermetrik verwendet. Dies ist vorteilhaft, wenn der Speicher nicht ausreichend ist.
- CPU over-commitment: Dies ist eine Option zum Erzwingen eines maximalen vCPU (virtuelle CPUs): pCPU (physikalische CPUs)-Verhältnisses im Cluster. Sobald der Cluster diesen definierten Wert erreicht, können keine zusätzlichen VMs eingeschaltet werden.

6 Network-Aware DRS
DRS betrachtet nun auch die Netzwerknutzung eines ESXi Hosts. Dabei beobachtet DRS die Tx- und Rx-Raten der verbundenen physikalischen Uplinks und vermeidet das Platzieren von VMs auf Hosts, die zu mehr als 80 % genutzt werden. DRS reagiert nicht reaktiv auf der Grundlage der Netzwerknutzung, sondern nutzt die Netzwerknutzung als zusätzliche Kontrolle, um zu ermitteln, ob der aktuell ausgewählte Host für die VM geeignet ist. Diese zusätzliche Eingabe verbessert die Platzierungsentscheidungen von DRS.
Bei Fragen oder Anregungen, melden Sie sich gerne bei uns!
Stefan Bast

Stefan Bast ist seit Januar 2012 für Proact Deutschland tätig. Sein Schwerpunkt liegt auf den Technologien von VMware und NetApp. Außerdem richtet sich sein Fokus auf die ergänzenden Datacenter- und Cloud-Security Lösungen von Trend Micro, wie z.B. Deep Security oder ServerProtect. Neben den Tätigkeiten im Consulting ist er auch als Trainer im VMware Umfeld aktiv.



