- Juniper Branch-SRX automatisiert installieren
- Günstiges, serielles „Out Of Band Management“
- Optischer Interconnect mit Branch SRX Firewalls
- Juniper Firefly Perimeter im Labor und freier Wildbahn
- Latenzen richtig messen und verstehen
- Datenblatt und Realität: Stromverbrauch von Juniper Geräten
- BGP Route Reflection mit JunOS
- Junos SNMP Utility MIB – oder: Wie monitore ich Werte die eigentlich nicht in SNMP vorhanden sind?
Juniper stellt mit seiner „Branch SRX“ Serie für den normalen und gehobenen Mittelstand eine sehr flexible und auch preissensitive Plattform für Firewalling, VPN und Routing bereit.
Durch den sogenannten „Chassis Cluster“ besteht die Möglichkeit Hochverfügbarkeit zum administrativen Aufwand eines Einzelsystems zu bekommen, indem man zwei Firewalls zu einer logischen kombiniert.
Soweit die Theorie und auch die Praxis, wenn man sich genau an die entsprechenden KB-Artikel halten kann. Spannend wird es, wenn Anforderungen wie z.B. das Aufteilen des Clusters auf zwei Rechenzentren ins Spiel kommen.
Damit man mit einer SRX-Firewall so einen Chassis Cluster bilden kann, müssen nämlich ein paar Voraussetzungen erfüllt sein:
- Die ControlPlane muss zwischen den Systemen geteilt werden (Interfaces fxp1)
- Die DataPlane muss zwischen den Systemen geteilt werden (Interfaces fab0 bzw. fab1)
- Optional, wenn man auch L2-Switching zwischen beiden Nodes machen will, braucht es auch swfab0 und swfab1.
- Die Latenzen sollten nach Juniper Best Practises nicht über 100ms liegen (siehe Quelle 003)
01: Das Problem
Hat man all die oben genannten Anforderungen erfüllt, kann es passieren, dass man feststellt, dass man eigentliche ein optisches Medium zwischen den beiden Firewalls braucht – wie z.B. bei einem unserer Kunden, da gab es schlicht und ergreifend einfach kein Kupfer zwischen den RZs.
Da die Branch SRX-Firewalls, auch die mit Option auf einen optischen Port, zumindest den ControlPlane Traffic (fxp1) über ein Kupfer Interface leiten wollen, steht man dann natürlich ziemlich dumm da.
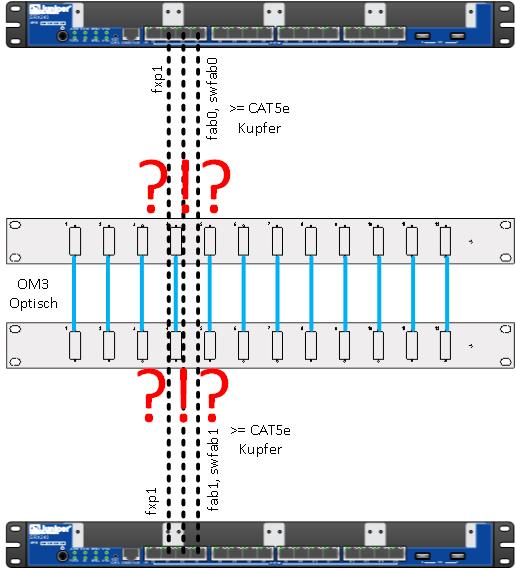
02: Die Lösung von Juniper Networks (aka Hack No.1)
Die erste Lösung kommt direkt aus der KB-Kartei von Juniper und sieht einfach zwei (oder mehr) Switches vor, welche die Verbindung zwischen den beiden Clusternodes übernehmen.
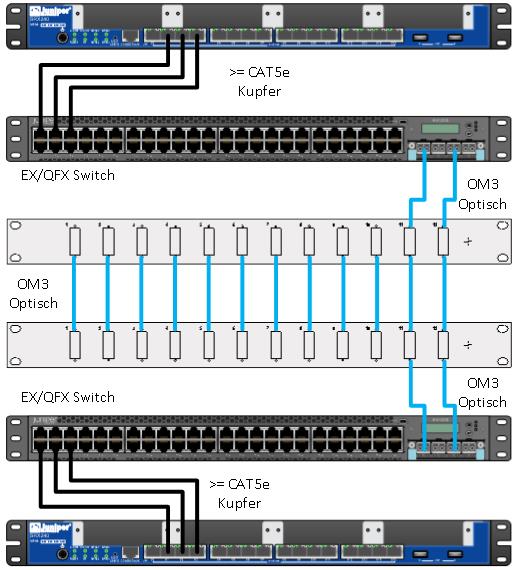
Hierbei sind jedoch einige Nachteile zu beachten:
- Performance: Wenn die Switches auch für andere Dinge wie z.B. Frontend Traffic genutzt werden, ist die Bandbreite nicht dediziert für den Cluster verfügbar. Dies kann in Peak Zeiten zu Problemen führen.
- Komplexität: Es müssen einige unübliche Parameter eingestellt werden (z.B. Ethertype und das ominöse VLAN4094). Dabei gibt es das Problem, dass man nur mit weiteren Verrenkungen („no-carry bei der SRX“, QinQ, Compella, …) mehr als einen SRX-Cluster in dieser Infrastruktur betreiben kann.
- Kosten: Die zwei Switches kosten, sofern noch nicht vorhanden, auch ordentlich Geld in Anschaffung und Betrieb.
Aber es gibt auch Vorteile, welche zu nennen sind:
- Einfacher Support: „Juniper weiß davon“ und man kann sich auf KBs beziehen. Ich will hier bewusst nicht „supported“ und „unsupported“ in den Mund nehmen, da beide Lösungen von Juniper den vollen Support haben, das habe ich mir per Anfrage ans JTAC(Juniper Networks Technical Assistance Center) bestätigen lassen.
- Lange Reichweite: Mit entsprechenden Switchen können auch lange Stecken überbrückt werden – hier bitte auf die Interface Buffers achten, die vergisst man sehr gerne (Faustregel: Man sollte mindestens 75ms bis 100ms Traffic in den Interfacebuffers halten können, mehr ist aber nicht immer besser, denn dann droht der BufferBloat!).
- „Faserredundanz“ möglich: Um sich einfach gegen den Ausfall einer Faser zu schützen, kann man bei der Switchlösung einfach einen LACP-Channel oder vergleichbares bauen und ist damit sehr einfach am Ziel.
03: Die Lösung von teamix (aka Hack No.2)
In einem Kundenprojekt hatten wir die Herausforderung in einer Umgebung, in der es zwischen den beiden RZs zwar genug freie Fasern, aber keine Kupferpatches gab. Somit haben wir nach einer einfachen und kostengünstigen Lösung gesucht und sie in simplen Medienconverten gefunden.
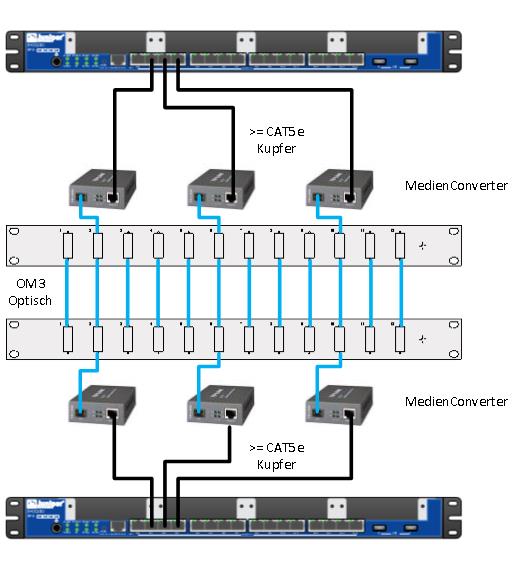
Die Vorteile dieser Lösung sind:
- Performance: Die Bandbreite ist dediziert für die Verbindungen zwischen den Clusternodes vorhanden und es gibt keine Buffers die man beachten müsste.
- Komplexität: Es ist wirklich einfachst, sofern man den Stromkabelwust der Medienconverter im Griff hat.
- Kosten: 20,35 EUR pro Converter (Stand 11/2014) zzgl. die Optiken sollten eigentlich in jeder IT-Portokasse zu finden sein.
Auch hier gibt es eine Kehrseite der Medaille, die sich in folgenden Nachteilen spiegelt:
- Es sind MedienConverter, und die haben einen schlechten Ruf! 😉
- Kurze Reichweite: Leider kommt man halt nur so weit wie die Optik und die Fasern es schaffen, wenn man mal von exotischen Dingen wie aktives DWDM, u.Ä. absieht.
- Wenig bis kein Monitoring: Da die MedienConverter „unmanaged“ sind, gibt es keine Möglichkeit Linkqualitäten, etc. zu überwachen, daher sollte man dis Links so zuverlässig wie möglich ausgestalten. Keine Experimente am Ende der Spezifikationen ohne dass man weiß was man tut.
- Keine „Faserredundanz“: Da ein MedienConverter immer nur mit einer Faserstrecke betrieben werden kann und es i.d.R. keine Failovermechanismen gibt, kann dieser Lösungsansatz keine „Faserredundanz“ bieten.
04: Schlusswort
Welche von beiden Lösungsansätzen man wählt bleibt jedem selbst überlassen. Ich hoffe jedoch, das Problem und die möglichen Lösungen so gut wie möglich beschrieben zu haben und weise wie immer darauf hin, dass Feedback gerne im Kommentarbereich oder direkt per eMail hinterlassen werden kann.
Ich danke an dieser Stelle folgenden Personen für Motivation, Input und Generierung von (Zeit) Ressourcen:
- Gowtham Perumal vom JTAC, der sich bei der Beantwortung meiner Fragen genau so viel Zeit gelassen hat, dass die Erstellung eines Blog-Artikels sinnvoll erschien.
Just kidding, Gowtham, habe das Thema ja auch nur mit Priority „4 – Low, No Escalation“ eingekippt. 🙂 - Christian Deckelmann von teamix, der sich bei uns intern sehr auf der „Netze-Team“ Mailingliste engagiert und es kaum einen (sinnvollen) Post gibt, den er nicht beantwortet.
- Simon Polke von Hengeler Mueller, der mir heute 8h Fahrtzeit Nürnberg Düsseldorf erspart hat und ich somit die Muse haben konnte, diesen Artikel zu schreiben.
05: Quellen
Richard Müller

Richard Müller ist Geschäftsführer der Proact Deutschland GmbH. Den "kreativen" Umgang mit Computern und Datennetzen lernte er schon im Schulalter. Bis heute hat Richard eine Begeisterung für technisch brilliante Konzepte und Lösungsansätze in den Bereichen IT-Infrastruktur - hier vor allem alles rund ums Netzwerk.




Hey Richi,
schöner Artikel, aber eins noch zu Medien Konvertern. Es gibt auch richtig coole Lösungen, siehe Allied Telesis MCF2000 !!! Die hab vor Jahren mal angeschafft, um eben auch von Kupfer auf Glas zu konvertieren. Die Dinger sind deutlich intelligenter als normale MCs und können auch richtig gemanaged und überwacht werden. 🙂 Und sooo teuer ist das Zeug auch nicht ! War damals (vor ca. 7 Jahre) drastisch günstiger als SFP-based Gigabitswitch für die Aggregation.
Gruß
Tschokko