- Juniper Branch-SRX automatisiert installieren
- Günstiges, serielles „Out Of Band Management“
- Optischer Interconnect mit Branch SRX Firewalls
- Juniper Firefly Perimeter im Labor und freier Wildbahn
- Latenzen richtig messen und verstehen
- Datenblatt und Realität: Stromverbrauch von Juniper Geräten
- BGP Route Reflection mit JunOS
- Junos SNMP Utility MIB – oder: Wie monitore ich Werte die eigentlich nicht in SNMP vorhanden sind?
Gerade im Bereich Datacenter Switching ist inzwischen allseits bekannt, dass neben den Portgeschwindigkeiten (1,10,40,100 GBit/s) und der Oversubscription-Ratio (Idealerweise keine) auch die Latenz eine essentielle Rolle bei Performancebetrachtungen spielt.
Früher waren niedrige Latenzen bekannterweise ein Monopol für die FibreChannel-Fraktion. Ethernet wurde damals bestenfalls müde belächelt oder als Kinderspielzeug abgetan.
Heute kann jeder „normale“ Datacenter Switch FCoE und hat mit nativem FibreChannel vergleichbare Latenzen. Dabei unterbieten sich die Hersteller in immer wahnwitziger anmutenden Latenzen im Submikrosekundenbereich.
Erstaunlicherweise findet man jedoch fast nie Angaben zu den angewandten Methoden, welche einen nicht unerheblichen Einfluß auf das Ergebnis haben – in Einzelfällen sogar so extrem, dass man bei einem Messverfahren sogar „negative Latenzen“ erhalten kann. Zeitreisen gibt es jedoch leider nur in StarTrek.
Dieser Artikel soll hier etwas Licht ins Dunkel bringen.
Um sich im Dschungel der Latenzen besser zurechtzufinden muss man eigentlich nur ein paar Dinge wissen:
- Welche Messgeräte und Messbedingungen wurden angewendet?
- Welches Forwarding-Verfahren nutzt ein Switch? (Store-And-Forward oder Cut-Through)
- Welches Messverfahren wurde angewendet um die Latenzangabe zu erreichen?
Messgeräte und Messbedingungen:
Bei den Messgeräten gibt es weltweit nur zwei ernstzunehmende Hersteller (IXIA und Spirent), welche beide verständlicherweise sündhaft teuer sind und nur in den Labs von Herstellern und großen ISPs bzw. Carriern zu finden sind. Dieses Netzwerktestequippment hat wie jedes andere Testequippment auch eine Messgenauigkeit, welche bei den Tests zu berücksichtigen und anzugeben ist (Frei nach dem Motto: Wer falsch misst, misst Mist).
Hat das Testgerät beispielsweise eine Messgenauigkeit von +-150ns kann es bei einer realen Latenz von 500ns Ergebnisse zwischen 350ns und 650ns liefern, was heute ein himmelweiter Unterschied ist.
Bei den Messbedingungen ist zu beachten, sollte man jemals das Glück haben, selber Testreihen an Hardware durchzuführen, dass Faktoren wie Kabellängen, Transciever, Switchload einen mitunter signifikanten Einfluss auf das Ergebnis und dessen Genauigkeit haben. Es sollte versucht werden diese Parameter immer gleich zu halten.
Wie man klar erkennen kann ist das Messen von Latenzen nicht gerade kostengünstig und einfach. Daher muss man sich als „Ottonormal-Netzwerker“ in der Regel mit den Herstellerangaben abfinden, kann diese jedoch kritisch hinterfragen.
Forwarding-Verfahren: „Store-and-Forward“
Bei diesem Verfahren empfängt ein Switch das gesamte Paket auf dem Ingress-Port und beginnt danach erst das Paket auf dem Egress-Port zu senden. Dadurch wird offensichtlich, dass die Latenzen dieses Verfahrens sicherlich nicht die kleinsten und obendrein noch abhängig von der Linkgeschwindigkeit und Paketgröße sind (Ein 9128 Byte großer Frame auf 1GE braucht sicherlich mehr Zeit komplett in einem Switch „reinzukommen“ als ein 64 Byte Frame auf 40GE).

Forwarding-Verfahren: „Cut-Through“
Hier wird sofort begonnen den Frame auf dem Egress-Port zu senden, wenn die Destination bekannt ist. Konkret kann das passieren nachdem die ersten 6Byte, welche die Destination-MAC enthalten, übertragen wurden.
 Dass ein „Cut-Through“ Switch die Daten bzw. Pakete schneller zum Ziel bringt ist offensichtlich.
Dass ein „Cut-Through“ Switch die Daten bzw. Pakete schneller zum Ziel bringt ist offensichtlich.
„Good News“ ist, dass nahezu jeder Switch heute nach diesem Verfahren arbeitet.
Messverfahren „Last-In, First-Out“ (LIFO)
Bei LIFO wird die Zeit gemessen vom Zeitpunkt an, wo das letzte Bit in den Switch eingeht und dem Zeitpunkt wo das erste Bit den Switch verlässt.

Durch das Schaubild wird klar, dass es bei diesem Messverfahren bei „guten“ Cut-Through Switchen zu negativen Latenzen kommen kann – Details und Rechenbeispiel ein wenig später. Daher ist dieses Verfahren auch am wenigsten aussagekräftig und sollte nicht (mehr) als Vergleichsreferenz zu Rate gezogen werden.
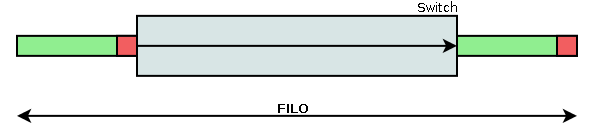
Messverfahren „First-In, Last-Out“ (FILO)
Dieses Verfahren misst die Zeitspanne vom Eingehen des ersten Bits eines Pakets in den Switch bis zum Verlassen des letzten Bits eines Pakets.
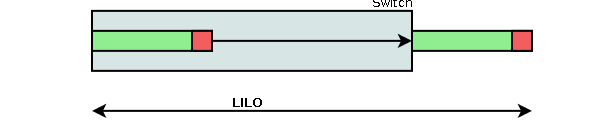
Messverfahren „Last-In, Last-Out“ (LILO) und „First-In, First-Out“ (FIFO)
LILO misst die Zeitspanne vom Eingehen des letzten Bits eines Pakets in den Switch bis zum Verlassen des letzten Bits eines Pakets.
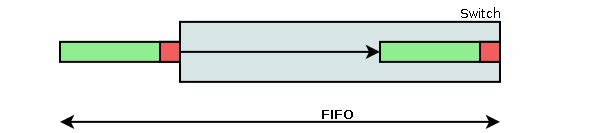
FIFO gibt die Zeitspanne an, die vom Zeitpunkt des Eingehens des ersten Bits eines Pakets in den Switch bis zum Verlassen des ersten Bits eines Pakets vergeht. FIFO wird als Messverfahren in RFC1242 definiert.
 Die LILO und FIFO Werte eines Switches sind, gleiches Ingress und Egress Medium vorausgesetzt, nahezu identisch. Da FIFO (warum auch immer) die leichter zu verstehende Kenngröße ist, wird diese jedoch häufiger verwendet.
Die LILO und FIFO Werte eines Switches sind, gleiches Ingress und Egress Medium vorausgesetzt, nahezu identisch. Da FIFO (warum auch immer) die leichter zu verstehende Kenngröße ist, wird diese jedoch häufiger verwendet.
Mit Hilfe von LILO/FIFO können alle anderen Messwerte berechnet werden, somit ist diese Kenngröße universell (siehe RFC4689):
- LIFO = FIFO-(Paketgröße/Link Geschwindigkeit)
Hier kann man sehr schön sehen wie man „Negative Latenzen“ mit einer LIFO Messung erzeugen kann. Beispiel
0,6µs FIFO Latenz, bei 9000 Byte Paketgröße und 1GBit/s Link Geschwindigkeit = 0,6*10^-6s – (9000*8Bit/1*10^9Bit/s) = -71µs Latenz! Yeah! - FILO = FIFO+(Paketgröße/Link Geschwindigkeit)
Sonstige wichtige Kriterien
Neben den reinen Zahlenwerten und dem Messverfahren der Latenzen (idealerweise FIFO, da am aussagekräftigsten und einleuchtensden) sind noch folgende weitere Kriterien bei der Latenzbewertung relevant:
- Deterministisches Verhalten bei unterschiedlicher Auslastung (Art und Menge der Daten, aktive Ports, welcher Port).
Konkret kennen wir ein Beispiel aus dem High Frequency Trading (HFT) wo Kunden als Kritierium haben, dass alle Ports gleich schnell sind und nicht beispielsweise die ersten Ports einige Nanosekunden schneller bedient werden als die letzten Ports eines Switches. Die könnten ja die Aktien schneller handeln als die Kunden auf den „billigen Plätzen“. - Geschwindigkeit des physikalischen Mediums und Transcievers (Serialisierungslatenz)
Dass ein Bit auf einem 1GE Interface mehr Zeit braucht um übertragen zu werden als auf einem 10GE oder 40GE Interface ist mathematisch offensichtlich, wird aber oftmals nicht in den Herstellerangaben berücksichtigt, ebensowenig die unterschiedlichen Latenzen einzelner Transciever-Typen welche durchaus unterschiedlich sein können.
Minimale Serialisierungslatenz = Paketgröße/Linkgeschwinigkeit (Beispiel: 64Byte auf einem 10GE Link = 64*8Bit/10*10^9Bit/s = 51ns)
Tabelle: Einige ausgewählte Datacenter Switches und deren Latenzen
Zu guter Letzt hier noch eine (unvollständige und unverbindliche) Tabelle mit verschiedenen Latenzen, verschiedener Switchhersteller. Verbesserungsvorschläge gerne mit Quelle und Name in die Kommentare posten, ich nehme diese gerne in dem Blog-Post auf.
| Switch (Hersteller, Typ) | Messverfahren | Latenz | Quelle |
|---|---|---|---|
| Arista - 7124S | unbekannt | 0,583µs bis 0,661µs (64 - 9216 Byte) | arista.com |
| Arista - 7148S | unbekannt | 0,903µs bis 1,02µs (64 - 9216 Byte) | arista.com |
| Arista - 7148SX | unbekannt | 1,245µs bis 1,420µs (64 - 9216 Byte) | arista.com |
| CISCO - Nexus 7710 | unbekannt | 6µs | Englische Wikipedia |
| CISCO - Nexus 3500 | unbekannt | 0,25µs bis 0,19µs | cisco.com |
| CISCO - Nexus 6001 | unbekannt | 1µs | Unbekannt |
| CISCO - Catalyst 6500 | unbekannt | 11µs bei 10GE innerhalb einer Linecard | cisco.com |
| CISCO - Catalyst 4500 | unbekannt | 5µs bei 10GE | cisco.com |
| HP - Procurve 3500, 5400zl, 6200yl | FIFO | 4,5µs bei 10GE | Externer Link zum Manual |
| Juniper - QFX5100 | unbekannt | 0,6µs bei 10GE | Hersteller Veranstaltung |
| Juniper - QFX3500 | unbekannt | 0,8µs bei 10GE | Hersteller Veranstaltung |
| Juniper - EX4550 | unbekannt | 2µs bei 10GE | Hersteller Veranstaltung |
| Juniper - EX4300 | unbekannt | 3,02 µs bei 1GE 1,6 µs bei 10GE | Hersteller Veranstaltung |
| Juniper - EX4200 | unbekannt | 4,5 µs bei 1GE 3,2 µs bei 10GE | Hersteller Veranstaltung |
Links zum Artikel:
RFC1242: http://www.ietf.org/rfc/rfc1242.txt
RFC4689: http://www.ietf.org/rfc/rfc4689.txt
Richard Müller

Richard Müller ist Geschäftsführer der Proact Deutschland GmbH. Den "kreativen" Umgang mit Computern und Datennetzen lernte er schon im Schulalter. Bis heute hat Richard eine Begeisterung für technisch brilliante Konzepte und Lösungsansätze in den Bereichen IT-Infrastruktur - hier vor allem alles rund ums Netzwerk.




Hallo Richard,
in Deinem Artikel schreibst Du daß „die Latenz eine essentielle Rolle bei Performancebetrachtungen spielt.“ Kannst Du das bitte genauer erklären?
Danke
Andreas