Wer mit der Administration von Computer-Systemen zu tun hat, stößt früher oder später auf deren Protokolle. In Protokoll-Dateien, englisch Log Files, protokollieren z.B. Linux-Systeme Ihre Aktivitäten. Windows kennt dafür das Event Log. Auch vSphere ESX-Hosts sowie NetApp- und Juniper-Systeme protokollieren fleißig mit.
Wer es nur mit wenigen Systemen zu tun hat, die möglicherweise auch noch sehr einheitlich sind, der schaut bei Problemen einfach mal schnell ins Log. Und auch das Suchen klappt mit grep, grep -r, zgrep ganz gut. Und wo die letzten Protokoll-Meldungen drinnen sind, offenbart der find-Befehl. Doch wie behalte ich den Überblick, wenn ich nicht nur ein System habe, sondern viele? Und wie behalte ich den Überblick, wenn es nicht „nur“ Linux-Systeme, sondern auch NetApp ONTAP-, vSphere ESX-, Juniper- und andere Systeme sind? Und wie behalte ich den Überblick, wenn ich zusätzlich auch die Protokolle von Diensten wie Apache, MySQL, Postfix oder Anwendungen wie Ruby on Rails- und andere Web-Anwendungen einsehen möchte?
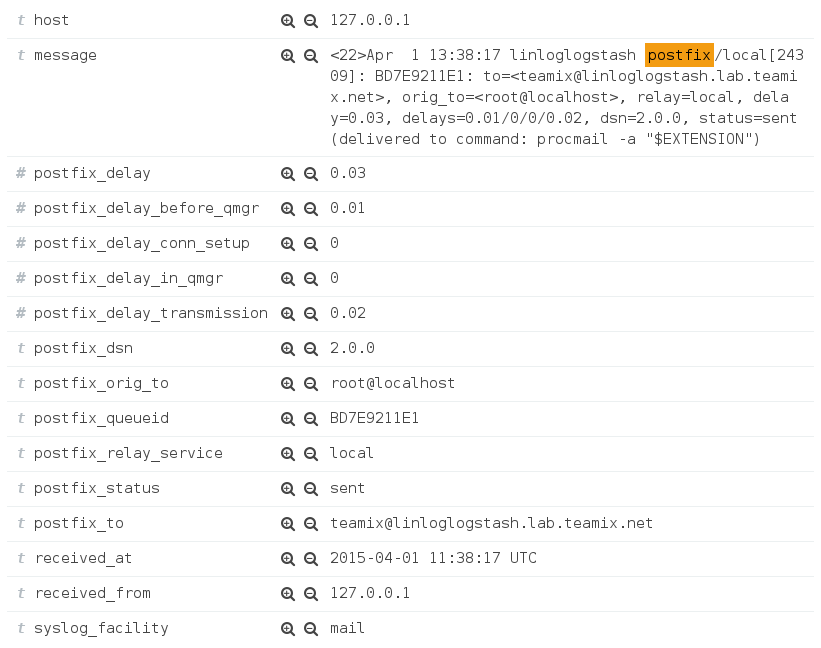
Logstash hat mit den passenden Grok-Filtern eine Postfix-Meldung in ihre einzelnen Bestandteile zerlegt, die sich selbstverständlich einzeln filtern lassen
Da habe ich zum einen unterschiedliche Log-Formate. Wenn auf einem Format Syslog steht, heißt das zum Beispiel noch lange nicht, dass standardisiertes Syslog nach RFC 3164 drin ist, wie unter anderem Rsyslog es verwendet. So liefert alleine vSphere ESX mindestens 3 unterschiedliche Syslog-Formate, NetApp ONTAP ein weiteres und so geht es weiter. Auch zu Datums- und Zeitangaben gibt es eine Menge unterschiedliche Vorstellungen.
Sicherlich lässt sich auch hier mit der Magie regulärer Ausdrücke vieles erledigen, was jedoch immer wieder manuellen Aufwand erfordert. Da scheint es sinnvoll, sich diesen Aufwand zumindest nur einmal zu machen. Aber sobald es zusätzlich darum geht, Logs auf unterschiedlichen Systemen in Beziehung zu setzen, zeigen sich schnell die Grenzen des klassischen und manuellen Ansatzes zur Analyse von Protokollen.
Hier kommt Logfile-Analyse zum Zuge. Und genau darum geht es in unserer neuen Schulung. Die Analyse großer Datenmengen, es müssen nicht mal unbedingt Protokoll-Daten sein, ist ein Trend-Thema im IT-Bereich. Immer mehr heterogene Systeme produzieren immer mehr Daten. Eine Herausforderung, die eine strukturierte und automatisierte Auswertung erfordert.

Mit Logstash in Elasticsearch aggregierte Syslog-Daten nach Top-Hosts und Severity. Die Auswertung macht mögliche Probleme auf einem Blick sichtbar. Die Farben lassen sich mit Kibana 4.0.1 allerdings derzeit noch nicht in der Oberfläche anpassen
Dieses Thema greifen Open-Source Werkzeuge wie Logstash, Fluentd, Kibana und Elasticsearch oder auch kommerzielle Lösungen wie vRealize Log Insight oder Splunk auf. In dem Kurs erkläre ich die grundlegenden Konzepte dahinter, erläutert was ein Log ist, welche Log-Formate verbreitet sind, welche Möglichkeiten es gibt, Log-Daten zu strukturieren und wie sich Log-Daten transportierten, speichern, indizieren und schließlich via Web-Oberfläche suchen und auswerten lassen. Es gibt im Rahmen des 3-tägigen Kurses natürlich die Möglichkeit, gängige und interessante Lösungen auszuprobieren und zu vergleichen. Kurs-Ziel ist dabei, eine Vorstellung von den einzelnen Werkzeugen zu vermitteln und Empfehlungen zu geben, was sich für welchen Einsatzzweck eignet.
Wir freuen uns, diese Schulung in Kooperation mit unserem Schulungspartner qSkills anzubieten. Die Premiere ist im Mai. Auf unserer Webseite finden Sie weitere Informationen zu unseren Schulungen und Kurstermine.
Martin Steigerwald

Martin Steigerwald beschäftigt sich seit Mitte der 90er Jahre mit Linux. Er ist langjähriger Autor von Artikeln für verschiedene Computer-Magazine wie die LinuxUser (linuxuser.de) und das Linux-Magazin (linux-magazin.de). Seit Herbst 2004 ist er als Trainer für Linux-Themen bei Proact Deutschland in Nürnberg tätig.



