
Das Erstellen von hochverfügbaren Kubernetes Clustern, in diesem Fall mit einem HAProxy als Load Balancer, muss kein Hexenwerk sein. Das Tool kubeadm erlaubt es uns innerhalb kürzester Zeit ein Kubernetes Cluster nach Best Practice aufzuziehen. Sowohl einfache Single Master Cluster, als auch hochverfügbare Lösungen mit mehreren Mastern lassen sich ohne großen Aufwand realisieren.
ACHTUNG: Der Begriff Hochverfügbarkeit bezieht sich hier nur auf die Kubernetes Komponenten, der Load Balancer kann immer noch einen Single Point of Failure darstellen, wenn er nicht auch redundant ausgelegt wird. Dies ist jedoch ein anderes Thema und wird in diesem Blogartikel nicht behandelt.
.Setup
In diesem Beispiel werde ich mit drei Mastern und fünf Worker Nodes arbeiten. Als Load Balancer kommt ein HAProxy zum Einsatz. Alle Maschinen laufen auf Basis eines Ubuntu 16.04. Wie üblich bei hochverfügbaren Kubernetes Clustern, darf natürlich auch der verteilte Key-Value Store Etcd nicht fehlen. Er sorgt dafür dass Konfigurationsdaten zwischen allen Master Knoten ausgetauscht werden.
Topologie
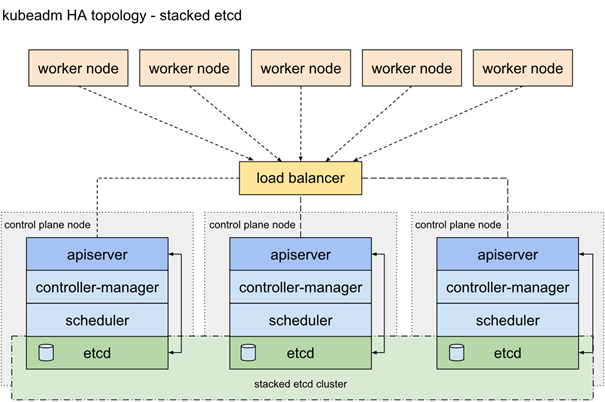
Bei einem Stacked Etcd Cluster laufen die Etcd Endpoints in Containern direkt auf den Mastern, was den großen Vorteil mit sich bringt, dass die Initialisierung und Konfiguration neuer Endpunkte automatisch und innerhalb kürzester Zeit geschieht. Das Gleiche gilt für die Generierung neuer Zertifikate für die Nodes. Der Gegenspieler zu einem Stacked Etcd Cluster wäre ein externer Etcd Cluster, bei dem alle Clients des Clusters eine eigene Maschine erhalten und nicht auf den Master Nodes laufen. Der Vorteil eines externen Etcd Clusters ist die erweiterte Hochverfügbarkeit, die durch die Trennung von Kubernetes Master und Etcd Knoten resultiert. Das heißt, ein Hostausfall eines Kubernetes Masters zieht nicht automatisch den Ausfall des Etcd Knotens mit sich. Und das Gleiche natürlich auch anders herum. Jedoch braucht man für diese Topologie die doppelte Anzahl an Hosts im Bezug auf die Master.
In diesem Fall kommt jedoch ein Stacked Etcd Cluster zum Einsatz.
Doch nun direkt zur Einrichtung des Clusters.
Schritt 1: Load Balancer einrichten
Als erstes werden wir unseren Load Balancer auf Basis von HAProxy aufsetzten. Um dies zu tun, installieren wir im ersten Schritt das HAProxy-Paket.
|
1 2 3 |
sudo add-apt-repository ppa:vbernat/haproxy-1.8 sudo apt-get update sudo apt-get install haproxy |
Wenn das Paket installiert ist, springen wir direkt zur Konfiguration des Load Balancers und fügen folgenden Text an das Ende der Datei haproxy.cfg:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
# vim /etc/haproxy/haproxy.cfg frontend kubernetes bind [LB_IP]:6443 option tcplog mode tcp default_backend kubernetes-master backend kubernetes-master mode tcp balance roundrobin option tcp-check server master01 [Master01_IP]:6443 check fall 3 rise 2 server master02 [Master02_IP]:6443 check fall 3 rise 2 server master03 [Master03_IP]:6443 check fall 3 rise 2 |
Erklärung: Wir erstellen ein Frontend, welches auf die IP des Load Balancers (bei [LB_IP] einfügen) und den TCP Port 6443 hört. Sobald dort eine Anfrage eintrifft, wird sie an das Backend kubernetes-master weitergeleitet. Dort wird nach dem „Roundrobin“-Prinzip ein passender Master für die Anfrage ausgewählt. Auch hier muss [Master01_IP], [Master02_IP] und [Master03_IP] selbstverständlich durch die realen IP-Adressen der Master-Maschinen ersetzt werden.
Nun müssen wir nur einen Daemon-Reload ausführen, um die Konfiguration des Load Balancers neu zu laden und hinterher den HAProxy Service neu zu starten:
|
1 2 |
sudo systemctl daemon-reload sudo systemctl restart haproxy.service |
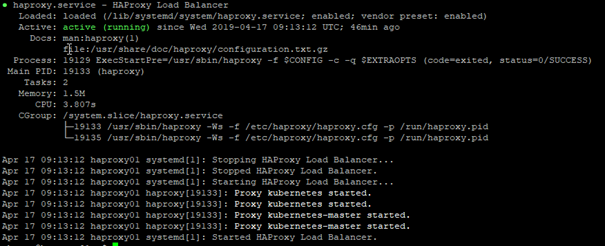
Jetzt können wir noch kurz überprüfen, ob die Konfiguration erfolgreich war:
|
1 |
systemctl status haproxy.service |
Schritt 2: Installation von Kubernetes & Docker
Auf allen Maschinen außer dem Load Balancer werden wir nun Kubernetes und Docker installieren. Dieser Schritt kann von OS zu OS leicht variieren, aber da dies kein Installationsguide von Kubernetes ist, ist der Prozess nur beispielhaft dargestellt und wird nicht weiter erklärt.
Zunächst werden alle Abhängigkeiten installiert:
|
1 2 |
sudo apt-get update sudo apt-get install apt-transport-https ca-certificates curl gnupg-agent software-properties-common |
Danach folgt die Installation von Docker:
|
1 2 3 4 5 6 7 8 9 |
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo apt key add – sudo add-apt-repository \ "deb [arch=amd64] https://download.docker.com/linux/ubuntu \ $(lsb_release -cs) \ stable" sudo apt-get update sudo apt-get install docker-ce docker-ce-cli containerd.io |
Und schlussendlich Kubernetes:
|
1 2 3 4 |
curl -s https://packages.cloud.google.com/apt/doc/apt-key.gpg | sudo apt-key add – sudo add-apt-repository "deb http://apt.kubernetes.io/ kubernetes-xenial main" sudo apt-get update sudo apt-get install kubeadm kubelet kubernetes-cni |
Schritt 3: Den ersten Master initialisieren
Für die grundlegende Clusterkonfiguration legen wir nun auf einem unserer Master Nodes eine Konfigurationsdatei an:
|
1 2 3 4 5 6 7 8 |
# vim kube.cfg apiVersion: kubeadm.k8s.io/v1beta1 kind: ClusterConfiguration kubernetesVersion: stable controlPlaneEndpoint: [LB_IP] networking: podSubnet: 10.30.0.0/24 |
[LB_IP] wird hier wieder durch die IP unseres Load Balancers ersetzt. Über das Pod-Subnetz kommunizieren später die Pods untereinander. Es ist im Normalfall nicht außerhalb des Clusters erreichbar.
Nun können wir auch schon mit Hilfe von kubeadm den ersten Master initialisieren.
|
1 |
sudo kubeadm init –-config=kube.cfg --experimental-upload-certs --certificate-key f8902e114ef118304e561c3ecd4d0b543adc226b7a07f675f56564185ffe0c07 |
Die Option --experimental-upload-certs sorgt dafür, dass Zertifikate automatisch auf jeden neuen Master und Worker des Clusters verteilt werden. Ohne dieses Argument müsste dies von Hand erledigt werden. Zusätzlich müssen wir einen sicheren Schlüssel für unsere Zertifikate übergeben. In meinem Beispiel habe ich ihn mit Hilfe von OpenSSL generiert.
ACHTUNG: Wenn Fehler beim Ausführen dieses Befehls entstehen, kann man sie mit der Option --ignore-preflight-errors=all ignorieren, dies ist aber nicht zu empfehlen.
Wenn dieser Schritt erfolgreich war, werden wir nun folgende Ausgabe erhalten:
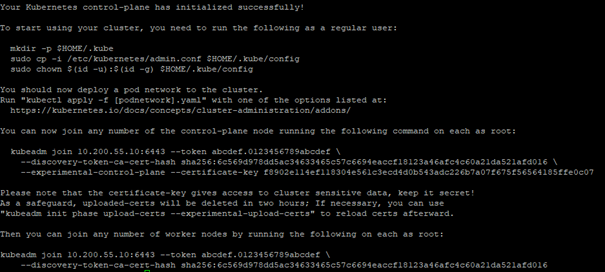
Wichtig sind die beiden Befehle, die mit kubeadm join beginnen. Diese brauchen wir später zum Hinzufügen weiterer Master- und Workernodes. Daher werden wir sie uns in einem Textdokument speichern.
Damit wir jetzt auch mit unserem Cluster interagieren können, müssen wir noch kubectl konfigurieren:
|
1 2 3 |
mkdir -p $HOME/.kube sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config sudo chown $(id -u):$(id -g) $HOME/.kube/config |
Der letzte Schritt auf unserem ersten Master ist nun ein Pod Network zu deployen. Ich habe mich für Weave Net entschieden. Weave ist ein Pod Network, welches direkt Out-Of-The-Box funktioniert und dem Benutzer die Option auf Verschlüsselung bietet. Es ist mit einem einfachen Befehl ausgerollt:
|
1 |
kubectl apply -f "https://cloud.weave.works/k8s/net?k8s-version=$(kubectl version | base64 | tr -d '\n')" |
Schritt 4: Weitere Master hinzufügen
Für das Hinzufügen weiterer Master Nodes genügt es, einen der beiden Befehle, die wir uns zwischengespeichert haben, auf den anderen Master Instanzen auszuführen. Wichtig hierbei ist es, den Befehl zu nutzen der die Option --experimental-control-plane beinhaltet und nicht den Zweiten, etwas kürzeren, den wir uns ebenfalls gespeichert haben. Es kennzeichnet diesen Node als Master.
|
1 2 3 |
sudo kubeadm join [LB_IP]:6443 --experimental-control-plane --token abcdef.0123456789abcdef --discovery-token-ca-cert-hash sha256:6c569d978dd5ac34633465c57c6694eaccf18123a46afc4c60a21da521afd016 --certificate-key f8902e114ef118304e561c3ecd4d0b543adc226b7a07f675f56564185ffe0c07 |
Auch hier kann im Anschluss nach Bedarf kubectl wieder konfiguriert werden.
|
1 2 3 |
mkdir -p $HOME/.kube sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config sudo chown $(id -u):$(id -g) $HOME/.kube/config |
Schritt 5: Worker Nodes hinzufügen
Der Prozess für die Worker Nodes ist der Gleiche, nur benutzten wir jetzt den zweiten Befehl aus unserem Textdokument (den ohne --experimental-control-plane).
|
1 |
kubeadm join [LB_IP]:6443 --token abcdef.0123456789abcdef --discovery-token-ca-cert-hash sha256:6c569d978dd5ac34633465c57c6694eaccf18123a46afc4c60a21da521afd016 |
Schritt 6: Cluster überprüfen
Sobald wir alle Master und Worker hinzugefügt haben, können wir nun auf einem der Master überprüfen, ob wir erfolgreich waren:
|
1 |
kubectl get nodes |
Wenn nun alle Nodes den Status ready zeigen, ist der Cluster bereit. Dies kann aber unter Umständen ein paar Minuten dauern.
Oskar Wortmann

Oskar ist seit September 2017 für die Proact Deutschland GmbH tätig. Seit 2019 ist er Teil des Cloud Teams und beschäftigt sich mit den Themen OpenSource und DevOps.



