Mit der Veröffentlichung von ONTAP 9.5 am 15. Januar ist es einmal an der Zeit sich die Entwicklung von ONTAP 9 einmal genauer anzusehen.
Zuerst einmal der Name.
Vielen ist noch Data ONTAP 8 in den zwei „Geschmacksrichtungen“ 7-Mode und Clustered bekannt. In den Major Releases 8.0, 8.1 und 8.2 wurden diese parallel entwickelt.
Seit 8.3 gibt es keinen 7-Mode (letzte Version 8.2.5P2) mehr und der Produktname lautete „clustered Data ONTAP„.
Diese Bezeichnung wurde aber schon mit dem nächsten Release wieder verworfen.
Da der 7-Mode nicht mehr existierte wurde der Name vereinfacht und lautete nur noch „ONTAP 9„.
Zeitgleich wurde ein neues Release Modell eingeführt, welches hier kurz erklärt wird.
Neben „ONTAP 9“ gibt es nun zwei neue Varianten. Cloud Volumes ONTAP und ONTAP Select.
Diese teilen sich die Code Basis mit ONTAP 9 und somit handelt es sich „nur“ um spezielle Varianten für bestimmte Einsatzzwecke:
- ONTAP 9
ist das Betriebssystem, dass auf den FAS und AFF Systemen von NetApp zum Einsatz kommt und ist aktuell noch der typische Einsatzzweck - Cloud Volumes ONTAP
Dabei handelt es sich um einen virtuellen Filer, der ONTAP als Betriebssystem nutzt und in einer Cloud, wie z.B. Azure oder AWS, eingesetzt wird.
Sie haben volle Zugriffsrechte und können die Dienste NFS, CIFS und iSCSI wie auf NetApp Hardware selbst verwalten und anderen (Cloud-)Systemen zur Verfügung stellen. - ONTAP Select
Ähnlich wie ONTAP Cloud ist es ein virtuelles Speichersystem. Es ist jedoch für den Einsatz auf eigener Hardware optimiert. Somit können Sie auf einem gängigen Server mit lokalen Festplatten einen Hypervisor (VMware oder KVM) installieren und ONTAP in einer virtuellen Maschine bereitstellen.
Auch hier können Sie den zur Verfügung stehenden Speicherplatz per NFS, CIFS oder iSCSI an andere Systeme verteilen.
Die Features in ONTAP 9.x
Gleich zu Anfang:
Diese Liste ist bei Weitem nicht komplett. Ich beschränke mich hier auf die aus meiner Sicht interessantesten Änderungen.
9.0 wurde am 01. September 2016 veröffentlicht und somit kommt hier ein „Best of“ der letzten 2 1/2 Jahre:
Storage Efficiency
Viele unserer Kunden interessieren sich vor allem für die Efficiency Features.
Also was hat sich hier alles getan:
- 9.0 Data Compaction:
Hierbei handelt es sich um ein komplett neues Feature. Im WAFL Dateisystem wird immer mit 4k Blöcken gearbeitet. Wenn mehrere dieser Blöcke nicht komplett genutzt werden, können diese nun in einem einzigen 4k Block zusammengefasst werden.
Als einfachstes Beispiel: Es werden in 4 Blöcken jeweils 1KB Speicherplatz belegt.
Ohne Data Compaction werden auf den Festplatten nun 12 KB Speicher benötigt.
Mit Data Compaction sind es nur 4 KB, da die 4 x 1KB in einem Block zusammengefasst werden. - 9.2 Cross Volume Deduplication (Inline):
Die „normale“ Deduplizierung ist vielen bereits bekannt. Diese funktionierte bis zu ONTAP 9.2 nur innerhalb eines Volumes.
Mit der Cross Volume Deduplizierung wurde diese Beschränkung aufgehoben und Volumes werden gegeneinander dedupliziert. Da dies nur innerhalb eines Aggregats passiert kann man also auch von einer „Aggregats-Deduplizierung“ sprechen. - 9.3 Cross Volume Deduplication (Background):
Die Funktion wurde ja schon beschrieben. In dieser Version wurde der Prozess jedoch noch einmal verbessert. In ONTAP 9.2 wurde die Cross Volume Deduplizierung nur beim Schreiben durchgeführt. Somit haben nur neu geschriebene Daten davon profitiert.
Mit ONTAP 9.3 wurde ein Background Task eingeführt, der die bereits vorhandenen Daten prüft und optimiert. - 9.4 Cross Volume Deduplication (manuelles Triggern)
Seit 9.4 gibt es nun auch einen Befehl mit dem man die vorhandenen Daten prüfen und optimieren lassen kann. Hier ein Beispiel:
1storage aggregate efficiency cross-volume-dedupe start -aggregate aggr1 -scan-old-data true
Hardware
Hier verzichte ich darauf, alle neuen Controller und mit welcher Version diese unterstützt werden zu beschreiben.
Das führt dazu, dass der Abschnitt relativ klein ausfällt.
Eigentlich gibt es m.E. nur eine wirklich interessante Neuigkeit:
Das Shelf DS460C
Wer die Shelf Bezeichnungen von NetApp entschlüsseln kann, dem erschließt es sich ggf. schon.
4 steht für 4 Höheneinheiten
60 steht für die Anzahl an Festplattenslots im Shelf
C steht für die Geschwindigkeit der IOM Module. C ist hier Hexadezimal und steht für 12Gbit/s
Also kann man nun 60 Festplatten (3,5 und / oder 2,5″ Platten) auf 4 HE unterbringen.
Mit den bisher verfügbaren Shelfs waren auf 4HE maximal 48 Platten nötig.
Snapshots
Gerade bei Backupsystemen hat man das Maximum von 256 Snapshots gerne mal erreicht, da man eine entsprechend lange Aufbewahrungsdauer haben wollte.
Seit ONTAP 9.4 wurde das Maximum an Snapshots eines Volumes auf 1023 vervierfacht.
Im Zusammenspiel mit anderen neuen Features kann dies durchaus interessant sein.
MetroCluster
Seit ONTAP 8.3 konnte auch im clustered Mode ein MetroCluster aufgebaut werden. Es waren 4-Node und 2-Node Konfiguration möglich.
Was hat sich seit ONTAP 9 noch getan?
- 8-Node MetroCluster
Seit ONTAP 9.0 ist auch eine MetroCluster Konfiguration mit insgesamt 8 Controllern möglich. Hier bei werden zwei s.g. „DR Groups“ aufgebaut in der jeweils 4 Nodes vorhanden sind.
Die Funktion ist mit zwei 4 Node MCs vergleichbar.
Es wird jedoch die Administration vereinfacht, da man weniger einzelne Cluster konfigurieren und administrieren muss. - MetroCluster IP
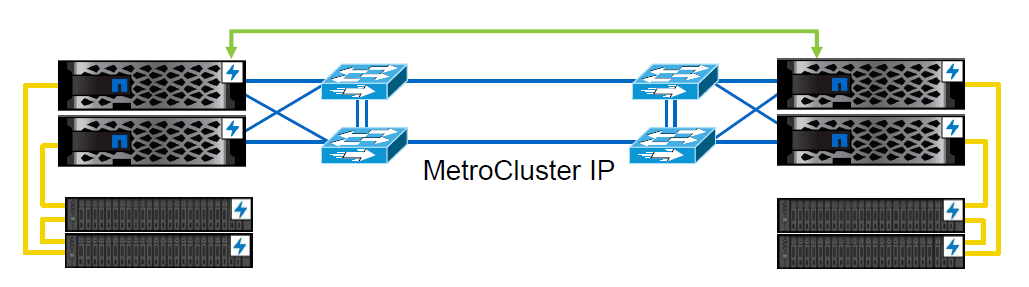
Seit ONTAP 9.3 ist nicht mehr zwingend ein FC Backend für einen MetroCluster nötig. Man kann das Backend nun auch über Ethernet Switche realisieren.
Mein Kollege Andreas Buhlmann hat dies bereits in einem Artikel erläutert. - unmirrored Aggregates
Direkt mit ONTAP 9.0 durften im MetroCluster auch wieder ungespiegelte Aggregate eingesetzt werden. Da stellt sich oft die Frage warum man einen MetroCluster betreiben und dann ein Aggregat nicht spiegeln sollte, da diese Daten bei einem Site Failover ja nicht mehr verfügbar wären.
In vielen Unternehmen sind Applikationen vorhanden, die schon innerhalb der Anwendung die Daten replizieren. Ein gern genommenes Beispiel ist hier die Microsoft Exchange DAG.
Wenn also eine Datenbank innerhalb der DAG hochverfügbar gemacht wird und zusätzlich auf einem gespiegelten Aggregat gespeichert wird sind die Daten 4 mal vorhanden. Durch „unmirrored Aggregates“ kann man somit Speicherplatz sparen.
- advanced Disk Partitioning (ADP)
Dieses Feature wurde ursprünglich für Entry-Level Systeme entwickelt, da man im clustered ONTAP immer zwingend ein Root-Aggregat benötigt. In Systemen mit wenigen Festplatten musste man also mindestens 2 Festplatten / SSDs für das Root-Aggregat opfern. Weitere Informationen hierzu finden Sie in einem Blog Artikel meines Kollegen Matthias Kellerer.
Dieses Problem hatte man aber auch in MetroCluster Konfigurationen.
Seit ONTAP 9.4 wurde ADP nun auch für MetroCluster IP Systeme freigegeben.
FabricPool
Hierbei handelt es sich um die Möglichkeit, Daten direkt aus ONTAP in einen kompatiblen externen Speicher auszulagern.
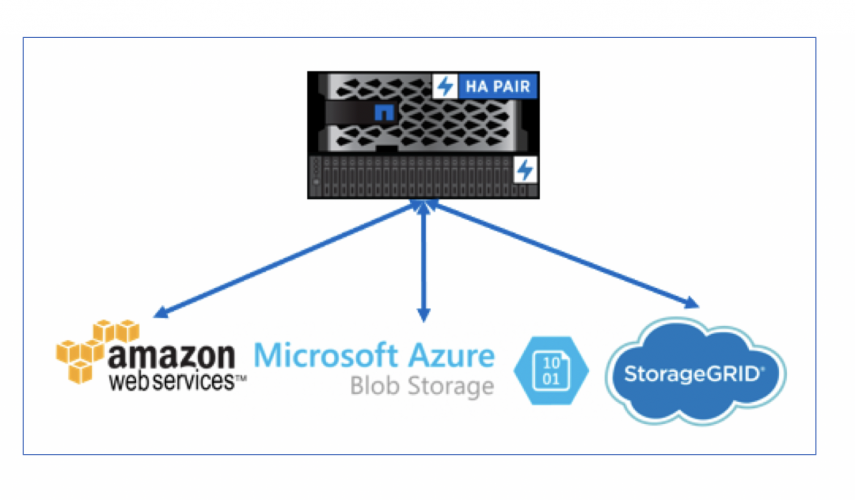
- 9.2
In dieser Version wurde das Feature erstmals freigeben. Man hatte die Möglichkeit, Snapshots nach AWS S3 oder S3-kompatible Services auszulagern, was den Speicherbedarf im ONTAP System signifikant reduzieren kann.
Das wirklich Schöne an dieser Funktion ist, dass es für das Frontend, also Anwender und / oder Applikationen, transparent ist.
Beim Frontendzugriff auf die Snapshots ist nicht ersichtlich, ob die Daten noch lokal gespeichert sind oder bereits nach S3 ausgelagert wurden. - 9.4
Mit diesem Release wurde FabricPool entsprechend weiterentwickelt. Als Zielspeicher ist nun auch Azure Blob supportet.
Außerdem wurde das Feature für ONTAP Select freigegeben. Zusätzlich wurde die „Auto“-tiering Policy eingeführt.
Nun kann ONTAP auch Daten aus dem aktiven File System (AFS) in den externen Speicher verschieben. Wenn eine Datei z.B. seit 60 Tagen nicht geöffnet wurde wird diese nach S3 ausgelagert und erst bei Bedarf wieder von dort abgeholt.
NetApp Volume Encryption
- 9.1
In ONTAP 9.1 wurde die Verschlüsselung von Volumes ermöglicht. So entsteht die Möglichkeit ohne spezielle Festplatten (NSE -> NetApp Storage Encryption) die Daten auf den Festplatten zu schützen.
Dabei kann man pro Volume entscheiden ob es verschlüsselt werden soll oder nicht.
Mit NSE und NVE (NetApp Volume Encryption) kann man die Daten auf den Festplatten sogar doppelt verschlüsseln. - 9.4
In diesem Release wurde eine Möglichkeit geschaffen eine komplette Node zu schützen. Bei Reboot muss erst der onboard key manager über ein Passwort entsperrt werden. So kann eine Node z.B. für einen Transport geschützt werden. - 9.5
ONTAP Cloud kann seit Version 9.5 dieses Feature nutzen. Somit können Sie die Daten, die Sie in einer Cloud gespeichert haben entsprechend schützen.
triple parity RAID Protection
Nach RAID-4 und RAID-DP kam noch eine dritte Raid-Konfiguration namens RAID-TEC hinzu.
Nun stellt sich natürlich die Frage, warum man sich gegen den Ausfall von 3 Festplatten innerhalb einer Raidgroup schützen sollte. Die Notwendigkeit für diese Technologie ergibt sich automatisch aus den größer werdenden Festplatten.
Vor allem in Backupsystemen mit SATA / NL-SAS Festplatten kann es ca. 100 Stunden, also etwas mehr als 4 Tagen, dauern, bis eine ausgefallene Festplatte wiederhergestellt wurde und das Aggregat wieder im Normalzustand ist. Während des Rebuilds darf nur eine weitere Platte ausfallen, ohne dass ein Datenverlust eintritt.
Mit RAID-TEC senkt man also die Wahrscheinlichkeit eines Datenverlusts.
Snaplock
Die aus den 7-Mode Systemen bekannte WORM (Write Once Read Many) Storage-Technologie wurde in ONTAP 9.0 auch im „clustered Mode“ wieder eingeführt. Somit ist es nun wieder möglich Aufbewahrungszeiträume für Ihre Daten zu forcieren.
SnapMirror
- 9.0
Das „global throttling“ konnte vor ONTAP 9.0 nicht verwendet werden und man konnte nur pro SnapMirror Beziehung einen Maximalwert konfigurieren. Somit musste man beim Anlegen oder Löschen von Beziehungen immer wieder manuell nacharbeiten.
Mit dem global throttling konnte man wieder alle aktiven Transfers auf einen Wert konfigurieren. - 9.5
Mit der aktuellen Version ist wieder SnapMirror synchronous (SM-S) möglich. Man kann somit Daten per SnapMirror synchron auf ein anderes NetApp System schreiben lassen. Dies war bis jetzt nur im MetroCluster möglich.
CIFS
Mit Version 9.0 wurden für das CIFS Protokoll noch folgende Features eingeführt:
- Workgroup Mode
Eine CIFS aktivierte SVM benötigte immer ein Active Directory. Diese Abhängigkeit wurde mit dem Workgroup Mode aufgehoben und man kann CIFS nun auch wieder ohne Domäne betreiben. - Support für die Microsoft Management Console
Dieses Feature war vielen schon im 7-Mode nicht bekannt, weshalb ich es hier kurz erkläre:
Man kann die MMC öffnen und sich mit der CIFS SVM wie mit einem Windows File Server verbinden. Hier hat man dann wiederum die gewohnte „Windows“-Oberfläche für die Verwaltung von offenen CIFS Sessions bzw. geöffneten Dateien.
Somit können nicht-NetApp-Admins CIFS einfacher bzw. wie gewohnt verwalten.
Storage QoS
Da auf einem Storage System in den seltensten Fällen nur ein Workload aktiv ist möchte man ggf. den wichtigen Workloads eine entsprechende Priorität zuweisen.
Hier hat sich seit 9.0 einiges getan:
- ONTAP 9.0
Eine Limitierung auf IOPS bzw. MB/s ist möglich.
Das Limit, dass zuerst erreicht wird beschränkt den Durchsatz bzw. die IOPS - ONTAP 9.2
Ab dieser Version kann man auf AFF Systemen „throughput floors“ definieren.
Einfacher gesagt kann man einem Volume oder ein Lun ein garantiertes Minimum (QoS min) zuweisen. - ONTAP 9.3
Mit diesem Release wurde „Adaptive QoS“ eingeführt.
Dieses Feature ändert die QoS Werte eines Volumes automatisch, wenn dieses vergrößert bzw. verkleinert wird. Somit kann man die Maximal- und Minimalwerte an die Größe eines Volumes koppeln. - ONTAP 9.4 / 9.5
Adaptive QoS wurde weiterentwickelt.
Mit 9.4 konnte man die Werte auf Volumes, Dateien und Luns anwenden.
Seit 9.5 wird nicht mehr die Größe des Volumes als Basis für die Berechnung verwendet, sondern der tatsächlich verbrauchte Speicherplatz. Zusätzlich kann man nun MB/s und IOPS spezifizieren.
Wie oben bereits erwähnt ist diese Liste nicht komplett.
Sie soll jedoch einen kurzen Überblick verschaffen, welche Entwicklung ONTAP in den letzten 2 1/2 Jahren gemacht hat.
Evtl. dient es Ihnen auch als eine Information, auf welche Version Sie updaten sollten, um eines der neuen Features nutzen zu können.
Wie gewohnt stehen wir Ihnen natürlich gerne mit Rat und Tat zur Seite.
Daniel Harenkamp

Daniel ist seit November 2015 bei der Proact Deutschland beschäftigt. Er ist als Professional Services Engineer im Bereich NetApp Hard- und Software, Virtualisierung und Backup unterwegs. Ob das Backup mit Commvault, Veeam oder den NetApp Produkten durchgeführt wird spielt für ihn dabei keine Rolle. Seine Kenntnisse den angrenzenden Gebieten wie z.B. der Microsoft Produktpalette sind ihm bei seiner Tätigkeit sehr hilfreich. Wenn dann noch Zeit bleibt ist er auch als Trainer tätig.



