UPDATE: Nach einem Hinweis von Falco in den Kommentaren zu diesem Artikel muss ich meine Aussage zu den Hypervisorbreakouts revidieren. Nach genauerer Recherche aufgrund des Hinweises im VMware Advisory, muss konstatiert werden, dass es mittels der Variante aus CVE-2017-5715 sehr wohl möglich ist, den Speicher des Hypervisor auszulesen und damit Daten anderer, eigentlich nicht sichtbarer VMs auf dem gleichen System auszulesen!
Seit Ende letzten Jahres sind im Internet diverse Gerüchte über eine massive Sicherheitslücke aufgetaucht, die alle Systeme (Linux, macOS, Windows) und alle Prozessorarchitekturen (x86, x64, ARM, Power, …) betrifft. Seit heute haben wir Gewissheit, dass das nicht nur Gerüchte waren: mit der Veröffentlichung von Meltdown/Spectre haben wir eine der flächendeckendsten Schwachstellen in der IT-Infrastruktur seit langem und es handelt sich nicht um einen Software-Bug, sondern um einen Designfehler in den CPUs selbst. In diesem Artikel werde ich versuchen, den doch sehr komplexen Hintergrund der Angriffe auf einigermaßen verständliche Begriffe herunter zu brechen, damit sich jeder ein Bild von den Auswirkungen und der Gefährdung machen kann. Etwas technisches Interesse und Geduld vorausgesetzt, werde ich hier den Hintergrund (grob) darstellen und erklären, was da eigentlich schiefgeht.
Mit Meltdown und Spectre sind gleich zwei verwandte, aber vom Grundprinzip her unterschiedliche Angriffe gegen die Speicherisolation in praktisch allen modernen CPUs bekannt geworden. Hierbei handelt es sich um eine Schwachstelle, die darin begründet liegt, wie moderne CPUs diese Speicherisolation implementieren und was diese tun, damit sie eine gute Auslastung (Performance!) haben. Diese beiden Mechanismen in Kombination ermöglichen die beiden Angriffe, die ich hier erklären möchte.
Hintergrund
Alle modernen CPUs (und „modern“ bezeichnet hier praktisch alles seit den frühen 1990ern) haben in ihren Architekturen einige Gemeinsamkeiten, die sich im Laufe der Jahre einfach als „der Stand der Technik“ etabliert haben und daher quasi überall (egal ob Intel, AMD, IBM Power oder ARM) vorhanden sind. Der eine Mechanismus ist die CPU-unterstützte Isolation von Prozessen untereinander (und in neueren CPUs auch VM, was praktisch auf dem gleichen Mechanismus basiert) und das andere ist „speculative Execution“. Im Folgenden werde ich beide Mechanismen (stark vereinfacht) erklären um dann am Ende dieses Artikels zu erklären, wie man diese Mechanismen austricksen kann, um Zugriff auf Daten zu bekommen, die man eigentlich nicht haben sollte.
Speicherisolation
In den Anfängen der CPUs lief alles, was auf einem System lief in einem großen Speicherbereich. Jeder Prozess hatte Zugriff auf alles, was einfach der Tatsache geschuldet war, dass CPUs sehr einfach gehalten werden mussten und meistens nur wenige und vertrauenswürdige Prozesse liefen. Diese Annahme wurde jedoch bald durch Mehrbenutzersysteme außer Kraft gesetzt und es wurde zu einem Problem, dass jeder einfach den Speicher des anderen ohne Kontrolle lesen und auch schreiben konnte. Des weiteren war es möglich, dass ein einzelner fehlerhafter Prozess das gesamte System instabil machte, da dieser Prozess auch unkontrolliert Speicher von anderen Prozessen (oder sogar des Betriebssystems) verändern konnte, die dann wiederum auch in unerwartete Zustände gebracht wurde und schließlich alles mit in den Abgrund zogen.
Die Abhilfe für dieses Problem heißt „Virtual Memory“: jeder Prozess bekommt seinen eigenen Adressraum zugeordnet und kann so gar nicht mehr sehen, was überhaupt noch an anderen Prozessen vorhanden ist und hat auch gar keine Möglichkeit mehr überhaupt auf fremde Adressen zuzugreifen, weil sein eigener Adressraum die anderen Prozesse nicht beinhaltet. Vereinfacht kann man sagen, dass es für jeden Prozess so aussieht, als ob er komplett alleine im Hauptspeicher wäre – fast jedenfalls: da jeder Prozess Betriebssystemfunktionen benötigt (Zugriff auf Hardwareressourcen wie Dateien, Netzwerk, USB usw.) bekommt jeder Prozess zusätzlich den Kernel mit in seinen Adressraum eingeblendet. Dieser Kernelbereich ist aber mit einer Zugriffskontrolle in der CPU versehen, so dass nur über definierte und erlaubte Schnittstellen in diesen Speicherbereich eingetreten werden kann.
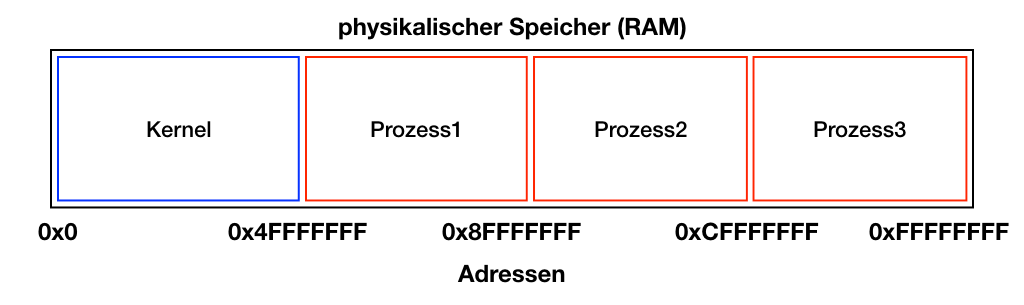
Das Bild zeigt die Sicht auf RAM ohne die Verwendung von „Virtual Memory“. Jeder Prozess hat vollständige Sicht auf alles. Wenn also jetzt Prozess1 (Speicherbereich 0x50000000 bis 0x8FFFFFFF) auf eine Adresse außerhalb dieses Bereich zugreifen will, dann kann er das einfach tun, da die Adressen bekannt sind und die Speicherbereiche sichtbar sind.
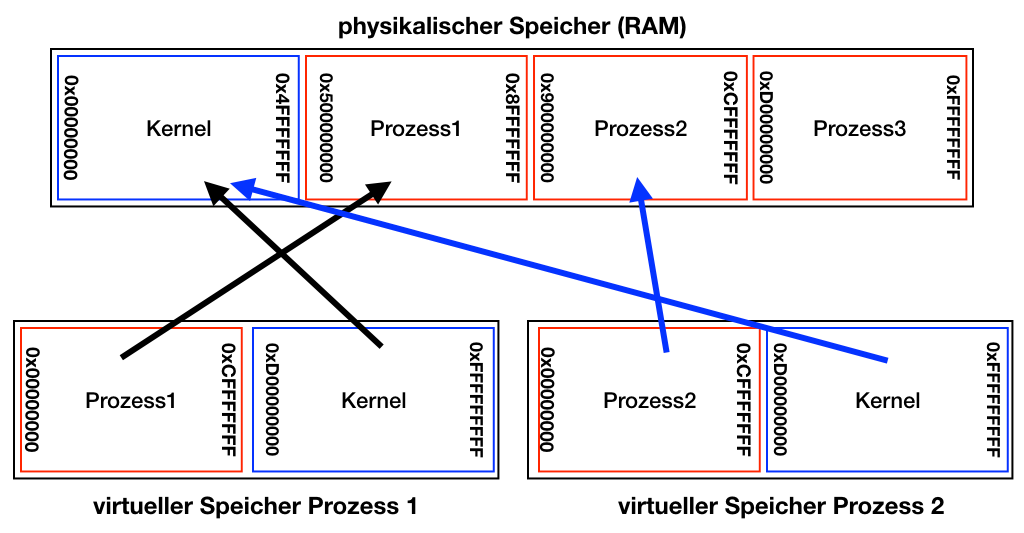
Mit „Virtual Memory“ ändert sich die Sicht der einzelnen Prozesse vollständig. Das physikalische RAM bleibt ihnen komplett verborgen und jeder Prozess startet aus seiner eigenen Sicht bei Adresse 0x00000000 und alle anderen Prozesse sind „nicht vorhanden“. Der Kerneladressbereich ab 0xD0000000 ist als „privilegiert“ markiert und damit Zugriffsbeschränkungen unterworfen. Die Vorteile sind sofort erkennbar: Wenn Prozess 1 „Amok läuft“ und wild Speicherbereiche beschreibt, dann zerstört er nur Datenstrukturen in seinem eigenen Adressraum. Die Pfeile in dem Diagramm stellen die sogenannten „Page Tables“ dar. Dies sind die Datenstrukturen, mittels derer die CPU (in Hardware mit Unterstützung des Betriebssystems) die Abbildung der virtuellen Adressen auf die tatsächlichen physikalischen RAM Adressen verwaltet. Zugriffe auf nicht erlaubte Speicherbereiche (z.B. Kernel oder außerhalb des eigenen Speicherbereichs) werden so schon von der CPU selbst unterbunden und resultieren unter Linux dann normalerweise mit dem berühmt berüchtigten „Segmentation Fault“ und der Prozess wird beendet.
Die PageTables werden pro Prozess verwaltet, was bedeutet, dass bei einem Kontextwechsel (Multitasking; ein Prozess wird stillgelegt und ein anderer soll laufen) die PageTables des einen Prozesses aus den Hardwareregistern der CPU entfernt werden (PageTable Flush) und die PageTables des neuen Prozess geladen werden müssen. Dies ist ein verhältnismäßig aufwändiger Vorgang, der Zeit kostet und daher vermieden werden möchte. Eine Optimierung ist genau die, dass die Kernel PageTables in jeden Prozess eingeblendet werden (die blauen Bereiche im obigen Diagramm), da anderenfalls bei jedem einzelnen Kernelaufruf die PageTables erst geflushed, die Kernel Tables geladen und im Anschluss wieder die Kernel Tables geflushed und die Prozess Tables geladen werden müssten. Das heißt, durch die Einblendung des Kernel in den Adressraum des Prozesses findet auch eine nicht unerhebliche Performanceoptimierung statt.
Speculative Execution
Alle modernen CPUs haben Pipelines. Das bedeutet, dass die CPU nicht einen Befehl nach dem anderen erst komplett ausführt und erst dann mit dem nächsten beginnt (was zu einer miserablen Auslastung der Hardware führen würde), sondern versucht in jedem Takt eine neue Instruktion anzufangen, die dann mehrere Stufen durchlaufen. Die Pipeline einer aktuell Haswell CPU hat zum Beispiel 15-19 Stufen, was bedeutet, dass sich zu einem gegebenen Takt jeweils 15-19 Befehle gleichzeitig in der Ausführung befinden können, jeweils in verschiedenen Stufen.
Pipelining löst das Problem, dass es bei relevanten Taktfrequenzen alles was für eine Instruktion notwendig ist in einem Takt durchzuführen. Statt also 15-19 Takte für einen Befehl zu benötigen (und damit nur alle 15-19 Takte tatsächlich einen Befehl auszuführen) wird in (fast…) jedem Takt ein Befehl in die Pipeline gesteckt und das Ergebnis erscheint dann 15-19 Takte später am Ende der Pipeline.
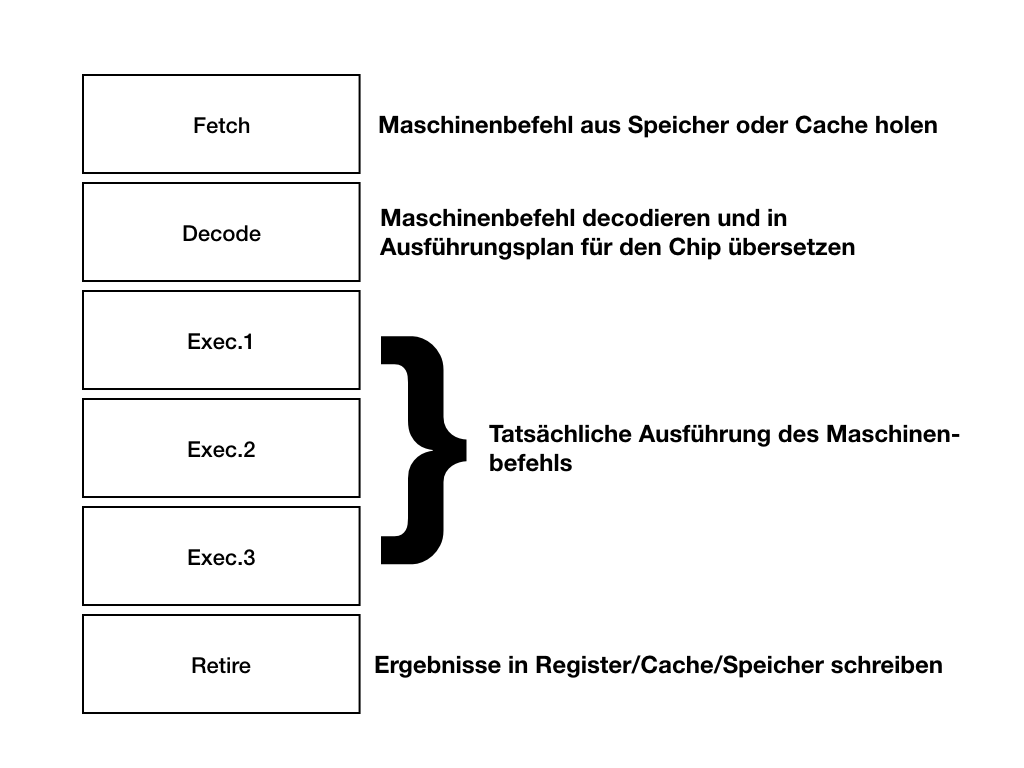
Das Bild zeigt eine (massiv vereinfachte) CPU Pipeline mit 6 Stufen. Idealerweie kann man in jedem Takt einen Befehl oben per Fetch abholen und kann das Ergebnis 6 Takte später unten bei Retire verwenden.
Diese (sehr erhebliche) Optimierung erkauft man sich allerdings teuer: Was wenn die Befehle in der Pipeline Abhängigkeiten untereinander haben? Wenn man z.B. (23+42)*17 als Maschinenbefehle schreibt, dann ergibt sich folgende Sequenz (Pseudocode):
|
1 2 |
Reg01 := 23 + 42 Reg02 := Reg01 * 17 |
Die letzte Instruktion hat hierbei ein Problem: Um den Befehl zu starten, müssen wir darauf warten, dass der Befehl in Zeile 1 sein Ergebnis in Register 1 (Reg01) geschrieben hat. In der Zeit passiert in der Pipeline nichts, es entsteht eine sogenannte Blase. Die letzten Instruktion (die Multiplikation) muss in der Decode Stufe warten, bis die vorhergehende Addition die Pipeline in der Retire Stufe verlassen hat.
Moderne CPUs implementieren eine ganze Reihe von Mechanismen, um die Auslastung der Pipelines hoch zu halten. Einer der sichtbarsten Mechanismen ist hier das HyperThreading: Statt dass die CPU einfach wartet und gar nichts macht holt sie sich einfach Instruktionen von der anderen virtuellen CPU und bringt diese zur Ausführung.
Ein weiterer Mechanismus widmet sich hier dem Problem der Verzweigungen (Branches) im Code. Das häufigste Vorkommen von Verzweigungen sind Scheifen. Der folgende Pseudomaschinencode zeigt eine einfache Schleife, die einen Block 10mal ausführt:
|
1 2 3 4 5 6 7 |
Reg01 := 10 ; LOOPSTART # Sprungmarke # Schleifenblock # mehrere Instruktionen Reg01 := Reg01 - 1 BNEZ Reg01, LOOPSTART # Branch if Not Equal to Zero; falls Reg01 nicht 0 ist, springe zu LOOPSTART # falls Reg01 0 war, geht es hier weiter |
Nach dem BNEZ Befehl stößt die CPU ebenfalls auf ein Problem: Was ist die nächste Instruktion? Springt der Code wieder zu LOOPSTART oder macht er einfach weiter? Der Inhalt von Reg01 könnte noch durch Instruktionen, die noch in der Pipeline sind, aber noch nicht abgeschlossen modifiziert werden. Hier kommt „Speculative Execution“ ins Spiel: Die CPU trifft einfach eine Vorhersage (Branch Prediction), ob der Branch genommen wird (also zu LOOPSTART springt) oder nicht, und macht erstmal einfach weiter, als ob diese Vorhersage stimmt. Falls sich die Vorhersage als richtig herausstellt haben wir nichts verloren und machen einfach weiter. Falls die Vorhersage falsch war werden die falsch ausgeführten Instruktionen verworfen und wir haben uns nicht mehr Nachteil eingehandelt, als das Warten auf das Ergebnis uns ohnehin eingebracht hätte. Selbst mit einer trivialen Branch Prediction, die einfach sagt „ein Branch tritt immer ein“ (d.h.: die Schleife dreht noch eine Runde) haben wir in unserem Fall neun richtige und nur eine falsche Vorhersage getroffen. Moderne Branch Predictions sind erheblich ausgefeilter als das triviale Bespiel und erreichen selbst in Randfällen Genauigkeiten von teilweise deutlich über 90%.
Die Securityprobleme
Meltdown
Kurz gesagt erlaubt Meltdown es unprivilegierten Prozessen die Abgrenzung zwischen Kernel und Prozessspeicher zu umgehen und damit dem vollständigen Kerneladressraum (der unter Linux und macOS das komplette physikalische RAM umfasst und unter Windows einen großen Teil des physikalischen RAM umfasst) auszulesen. Dies beinhaltet die Daten von allen anderen Prozessen und bei Kernel-Sharing Virtualisierung (Container wie zum Beispiel Docker oder LXC; nicht aber echte Hypervisor wie KVM, Xen (nicht im Paravirt Mode!), HyperV oder ESXi) alle dort laufenden Instanzen!
Meltdown macht sich zu Nutze, dass die CPU bei einer Branch Misprediction (falsche Vorhersage) unter Umständen Code ausführt, der eigentlich nie zur Ausführung hätte kommen können. Das wäre an sich noch nicht schlimm, da die Branch Prediction dies ja einige Takte später feststellt und die Ergebnisse der fälschlicherweise ausgeführten Instruktionen verwirft. Falls aber die spekulativ ausgeführten Befehle einen Speicherzugriff beinhalten, dann landen die angefragten Daten auch tatsächlich in dem gewünschten Register. Da die CPU bei spekulativ ausgeführtem Code keine Traps oder Exceptions ausführt (diese werden aufgestaut, bis die CPU weiss, ob die Branch prediction richtig oder falsch war) kann so durch geschickte Programmierung Code konstruiert werden, der beliebigen Speicher in die CPU Register lädt und dann noch ein paar Instruktionen darauf ausführen kann. Diese Instruktionen nutzt man dazu, um in einer entsprechend präparierten Datenstruktur im CPU Cache eine Markierung zu hinterlassen.
Über eine geschickte Seitenkanalattacke kann man jetzt auch feststellen, ob eine bestimmte RAM Adresse im CPU Cache vorhanden ist (die oben angesprochene Markierung im Cache), oder nicht. Damit hat man praktisch einen Sender und einen Empfänger gebaut:
- Der „Sender“ Prozess greift auf eine Adresse im Speicher zu, den er eigentlich nicht lesen kann.
- Die CPU führt den Zugriff durch und bemerkt dabei, dass es sich um einen Segmentaion Fault handelt und löst die Exception aus.
- Dadurch werden die folgenden Instruktionen eigentlich nie ausgeführt. Da die Branch Prediction jedoch solche Exceptions niemals vorhersagen kann provoziert der Zugriff ebenfalls eine Misprediction und die folgenden Instruktionen werden von der CPU noch spekulativ ausgeführt.
- Der nachfolgende Code schaut sich den Inhalt des zu gegriffenen Speichers an und basierend auf dem erhaltenen Wert greift er auf eine erlaubte Adresse zu und diese wird dadurch in den Cache geladen.
- Der Empfänger kann jetzt dadurch, dass er über bekannte Verfahren herausfindet, welche Adresse in Schritt 4 gecached wurde, den Inhalt des Kernelspeicher reproduzieren.
Beispiel:
Zwischen Sender und Empfänger existiert ein gemeinsames Array mit 256 Einträgen, bei dem durch geeignete Mittel sichergestellt ist, dass sich dieses nicht im CPU Cache befindet. Dies ist möglich, da Sender und Empfänger zum Beispiel vom gleichen Prozess aus gestartet werden. Der Sender lädt jetzt ein Byte aus dem Kernelspeicher (nicht erlaubt) und provoziert damit den Abbruch des Sender Prozesses. Die CPU führt aber noch eine Handvoll Befehle nach dem Zugriff spekulativ aus, da sie die Exception nicht vorhersehen konnte (an der Stelle würde niemals eine Branchprediction zur Anwendung kommen). Die folgenden Instruktionen schauen sich das geladene Byte aus dem Kernelspeicher an und greifen auf die entsprechende Stelle in dem gemeinsamen Array lesend zu. Wenn also der Wert 123 aus dem Kernelspeicher gelesen wurde, dann erfolgt ein Zugriff auf den Eintrag Nummer 123 in dem Array. Dieser lesende Zugriff provoziert, dass der entsprechende Arrayeintrag jetzt im Cache ist, und alle anderen Arrayeinträge nicht. Die CPU bemerkt anschließend, dass die spekulativ ausgeführten Instruktionen falsch waren und entfernt diese aus der Pipeline, ohne die Ergebnisse zu speichern. Die Änderung im Cache Zustand gehört aber nicht zu den rückgängig zu machenden Änderungen. So kann der Empfänger jetzt durch ebenfalls bereits bekannte Mechanismen herausfinden, dass Eintrag 123 im Cache ist und damit zurück folgern, dass der Wert des gelesenen Kernelbytes 123 war.
Dieses Verfahren wiederholt man jetzt für alle Kerneladressen und kann so den kompletten Inhalt des Hauptspeichers rekonstruieren.
Man sieht auch, dass das Verfahren recht umständlich ist, aber die Forscher konnten in Ihren Tests den Speicher mit ca. 500KB/s auslesen, was zwar langsam ist, aber das Problem nicht verringert: die Isolation zwischen Kernel und Userspace ist komplett aufgehoben und damit auch die Isolation zwischen den einzelnen Prozessen. Sämtliche Daten können von einer unprivilegierten Anwendung ausgelesen werden.
Spectre
Spectre ist eine verwandte, aber in Details unterschiedliche Attacke zu Meltdown. Während Meltdown primär auf Intel (kompatiblen) CPUs auftritt ist Spectre CPU unabhängig ausnutzbar und funktioniert auf vielen unterschiedlichen Plattformen. Analog zu Meltdown nutzt Spectre einen Seitenkanal in der Mikroarchitektur, um die Daten zu exfiltrieren (praktisch identisch zu dem Cache Array Trick in Meltdown).
Im Unterschied zu Meltdown konstruiert Spectre keinen eigenen Sender, sondern nutzt bereits vorhandenen Code des Zielprozesses und beeinflusst dann den Branch-Predictor der CPU so, dass gewünschte Instruktionen spekulativ ausgeführt werden. Im Gegensatz zu Meltdown liest Spectre Adressen aus, auf die der angegriffene Prozess tatsächlich zugreifen kann. Damit kommt es nicht zu einer Exception und dem Abbruch des beteiligten Prozess, da ja nur „legal“ lesbare Daten zugegriffen werden. Der Angriff besteht an dieser Stelle darin, dass es relativ einfach möglich ist beliebige Zielprozesse als Sender für den verdeckten Seitenkanal zu missbrauchen.
Aufgrund der Architektur und Auslegung aller Betriebssysteme ist das finden von geeignetem und ausnutzbarem Code für Spectre kein Problem. Es ist sogar so, dass bestimmte Best Practices für sichere Programmierung (Grenzen von Array Indices vor dem Zugriff testen) genau zu ausnutzbaren Code Mustern führen.
Zusammenfassung
Meltdown und Spectre brechen eine der grundlegendsten Annahmen auf modernen CPUs: die Isolation von Prozessen untereinander und von Prozessen gegenüber dem Kernel. Zugriffsrechte für Hauptspeicherzugriffe gelten einfach nicht mehr und alles, was im RAM ist, kann von jedem anderen Prozess ausgelesen werden. Die gute Nachricht ist, dass es sich bei beiden Angriffen nicht um Hypervisor Ausbrüche handelt. Beide Angriffe sind nach derzeitigem Kenntnisstand nicht in der Lage die Grenze zwischen Gast-VM und Hypervisor zu überwinden, auch wenn die prinzipiellen Techniken, die zur Anwendung kommen, dies nicht absolut ausschließen. Leider war meine Interpretation zur Funktionsweise nicht richtig. Eine Variante von Spectre/Meltdown erlaubt es sehr wohl auch den Speicher des Hypervisor auszulesen und damit auf den Inhalt anderer VMs zuzugreifen!
Was jetzt?
Keep calm, patch your systems and move on. Patches der großen Hersteller sind bereits draußen oder unterwegs.
Literaturverzeichnis
Aufgrund der großen Menge an Quellen und Informationen hier ein gesammelte Liste von Infos, die in diesen Artikel eingeflossen sind oder die weiter führende Informationen enthalten:
- Offizielle Seite zu Meltdown/Spectre
- Google Project Zero Blogeintrag
- CVE Einträge zu Spectre (2) und Meltdown
- Python Sweetness bringt als erster die Details zusammen
- LWN Artikel zu KPTI/KAISER mit ein wenig Spekulation vom 20.12.2017
- Gute Übersicht zu aktuellen Patches
Security Advisories (zum Zeitpunkt der Veröffentlichung)
- RedHat
- Debian
- Xen
- Ubuntu (Wiki), Security Advisories 1, 2, 3, 4, 5, 6, 7
- VMware
- SuSE
- Amazon (AWS)
- Microsoft
- Citrix
- Apple
- Mozilla Spectre Mitigation
- Cisco
- NetApp
Update 4.1.2018, 19:00h: Ein paar Unsauberkeiten in der Erklärung von Meltdown behoben.
Update 5.1.2018, 17:13h: mehrere Typos entfernt, Citrix Advisory hinzugefügt. h/t an Simon Lauger und Matthias Kellerer
Update 5.1.2018, 18:13h: Apple Advisory hinzugefügt
Update 6.1.2018, 15:23: Hypervisor Breakout doch möglich. Deutlichen Hinweis am Anfang eingefügt und entsprechende alte Passage per Strikethrough markiert.
Update 10.1.2018, 08:31: Ubuntu Security Advisories hinzugefügt, Link zu Sammelliste auf GitHub hinzugefügt
Update 12.1.2018, 10:44: Cisco, NetApp Advisories
Patrick Dreker

Patrick arbeitet seit 2006 bei der Proact Deutschland GmbH und bearbeitet dort die Themenfelder OpenStack, Cloud, Linux, Automatisierung und DevOps. Sein erster Linux Kernel war 1.2.13 und was Netscape und NCSA Mosaic waren, weiß er auch noch.




Danke für den sehr guten Beitrag – deutlich besser als was in der normalen Presse zu lesen ist.