Seit meinem letzten Artikel zum Thema BTRFS – BTRFS RAID 1: Selbstheilung in Aktion – im Januar 2015 sind mehr als vier Jahre vergangen. Haben Sie sich in der Zwischenzeit mal gefragt, ob der Autor dieses BTRFS immer noch im Einsatz hat? Und vielleicht auch, wie gut es funktioniert hat? Davon handelt dieser Artikel. Einen Ausblick auf BCacheFS und Stratis gibt es ebenfalls.
Vorne weg: Ja, der Dozent für Linux-Kurse hat BTRFS immer noch im Einsatz. Weiterhin auf dem ThinkPad T520. Und es läuft. Es verkraftet auch den Ausfall einer kompletten SSD, wie Sie weiter unten nachlesen können.
Natürlich geht das Ganze auch etwas ausführlicher:
Handhabung des freien Speicherplatzes
Zunächst einmal traten bis zum Linux Kernel 4.4 hin und wieder Probleme mit der Handhabung des freien Speicherplatzes auf. BTRFS suchte bisweilen so intensiv und lange nach freiem Speicherplatz, dass der Laptop für Minuten auf nichts anderes reagierte. Üblicherweise schaltete ich den Laptop nach einer Weile hart aus und startete ihn neu. Das Dateisystem konnte dadurch mitunter einige noch ungespeicherte Daten nicht mehr speichern. Es war jedoch ansonsten in Ordnung.
Wie kam es dazu? Die am BTRFS-RAID 1 beteiligten SSDs waren üblicherweise so voll, dass BTRFS den kompletten Speicherbereich des Block-Gerätes bereits entweder für Daten oder für Metadaten reserviert hat. In diesem Fall muss BTRFS innerhalb der üblicherweise 1 GiB großen Chunks nach Stellen mit freien Speicherplatz suchen und kann bei plötzlichen intensiven Schreibanforderungen nicht einfach einen weiteren Chunk belegen.
Das ist einer der Hintergründe, warum das Installationsprogramm von SLES/SLED ab Version 12 das Paket btrfsmaintenance standardmäßig mit installiert. Das löst regelmäßig den Befehl btrfs balance aus, um die Speicherbelegung innerhalb der Chunks auszubalancieren. Dazu kopiert der Befehl die Daten innerhalb der Chunks um. Er versucht dabei, die Chunks optimal zu füllen und dadurch, falls möglich, einige Chunks frei zu geben.
Bei den SLES12/15-VM-Vorlagen für meine Kurse habe ich es dennoch wieder entfernt, da es relativ viel I/O-Last verursachen kann, wenn mehrere VMs zu überlappenden Zeiten den Balance durchführen.
Seit Kernel 4.5 habe ich dieses Problem nicht mehr gesehen. Ich lasse das BTRFS weiterhin nicht regelmäßig balancieren, auch aufgrund der deutlich größeren verfügbaren SSD-Kapazität. Doch wie kam es dazu?
Was, wenn gleich eine komplette SSD ausfällt?
Das originale BTRFS RAID 1 lag auf einer Intel SSD 320 und einer Crucial m500 mSATA SSD. Wer damals aufmerksam die Neuigkeiten gelesen hat, weiß von dem Firmware-Bug in der Intel SSD 320. Bei diesem sogenannten „8 MByte-Bug“ konnte in seltenen Fällen nach einem Stromausfall der Fehler Bad Context 13x Error auftreten. In einem solchen Fall teilte die SSD-Firmware dem Betriebsystem 8 MB als Größe der SSD mit und lieferte als Daten nur noch Nullen zurück. Der Fehler entstand durch das Zusammenspiel von Firmware und Pufferkondensator. Genau dem Pufferkondensator, der dazu da ist, für das Speichern noch ungespeicherter Daten nach einem Stromausfall genügend Strom zu liefern.
Intel gab das Firmware-Update 0362 heraus. Dazu las ich damals, dass nach dem Einspielen des Updates entweder die SSD komplett kaputt sei, die Daten weg seien oder es einfach funktioniert. Nach einem Backup und dem Einspielen des Updates war klar: Ich hatte Glück. Es funktionierte einfach.
Doch es gab im Nachgang noch Stimmen die meinten, das Firmware-Update mache das Auftreten des Fehlers nur noch etwas unwahrscheinlicher, anstatt ihn komplett zu beheben. Ich ließ es drauf ankommen, schließlich hat der Laptop ja einen Akku, dachte ich mir.
Das ging auch jahrelang gut, bis ich im Hitzesommer 2018 den Laptop aufgrund eines Problems, an das ich mich nicht mehr erinnere, hart ausschaltete. Beim nächsten Neustart kam: Operating system not found. Eine Analyse mit einem von einem USB-Stick gebooteten GRML-Live-Linux offenbarte für die Intel SSD eine Größe von 8 MB und einen Haufen von Nullen anstatt der an sich gespeicherten Daten.
Der nächste Schritt war für mich zu sehen, inwiefern ich über die verbleibende Crucial-SSD noch auf die Daten zugreifen konnte. Das war in der Tat möglich. Aus Gründen der Datensicherheit erlaubt BTRFS in einem solchen Fall das Mounten standardmäßig nur via Mount-Option degraded. Es war dann möglich, die aktuellen Daten zu sichern. Und ich konnte das Dateisystem initial sogar im Lese-/Schreib-Zugriff einhängen.
Die erste Idee war, BTRFS einfach in das Profil single umzubauen, bei dem alle Daten auf einem Laufwerk liegen. Daher startete ich den entsprechenden btrfs balance-Befehl. Später lernte ich, dass ich die Intel SSD 320 mit einem Secure Erase wieder in einen verwendbaren Zustand bringen konnte. Daher brach ich den Befehl wieder ab.
Ab diesem Zeitpunkt erlaubte BTRFS jedoch das Mounten nur noch im Lese-Zugriff. Es fand Chunks im Profil single, das keinen Ausfall eines Datenträgers toleriert, und verweigerte das Mounten im Schreib-Zugriff, ohne vorher zu prüfen, inwiefern diese Chunks auf dem noch vorhandenen Datenträger liegen. Ein Verhalten, das in neueren Kernel-Versionen behoben ist.
Daher legte ich das BTRFS komplett neu an und kopierte die alten Daten via Rsync zurück. Natürlich plante ich die Intel SSD 320 nur noch einzusetzen, bis ein Ersatz ohne einen solchen Bug da war. Die Migration auf eine Samsung 860 Pro mit 1 TB Kapazität wäre demnach auch über btrfs replace möglich gewesen. Dabei würde BTRFS die Daten zur Laufzeit von der Intel SSD 320 auf die gleichzeitig angeschlossene Samsung 860 Pro umkopieren – ein sehr effizienter Vorgang.
Für eine möglichst optimale initiale Speicherbelegung entschied ich mich, das Dateisystem für die Migration noch einmal neu anzulegen und alle Daten von der Intel SSD 320 via Rsync rüber zu kopieren.
Und so laufen die BTRFS-Dateisysteme bis heute. Derzeit ohne Komprimierung, da die nun fast 1,5 TB SSD-Kapazität bislang locker ausreichen:
|
1 2 3 4 5 6 |
% df -hT -t btrfs | grep -v zeit Dateisystem Typ Größe Benutzt Verf. Verw% Eingehängt auf /dev/mapper/sata-debian btrfs 50G 24G 26G 49% / /dev/mapper/sata-home btrfs 300G 171G 128G 58% /home /dev/mapper/sata-daten btrfs 400G 281G 120G 71% /daten /dev/mapper/sata-build btrfs 20G 524M 20G 3% /var/cache/pbuilder |
So hat das BTRFS RAID 1 für /home bislang noch nicht den gesamten Speicherplatz des Block-Gerätes für sich reserviert (siehe Device unallocated).
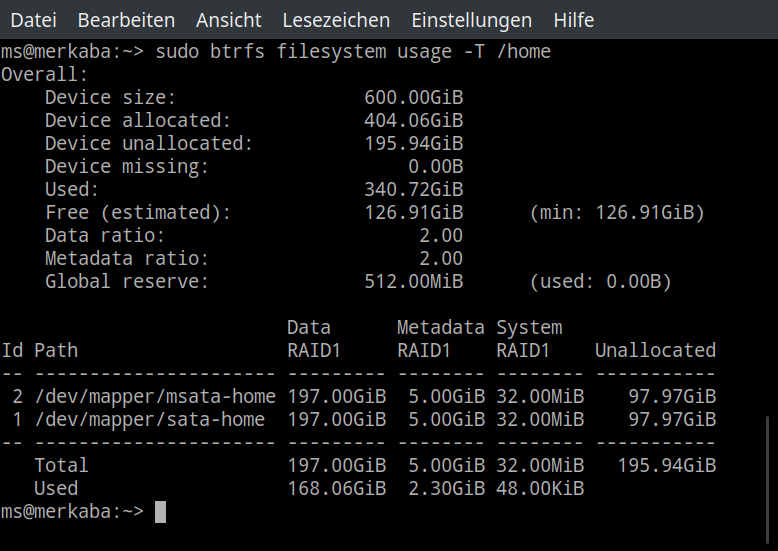
Hinweis: Während die Device-Angaben und Used sich auf den roh verfügbaren Speicher beziehen, der für RAID 1 wie in Data ratio und Metadata ratio angegeben durch 2 zu teilen ist, ist die Angabe bei Free (estimated) bereits auf das verwendete Blockgruppen-Profil für RAID 1 herunter gerechnet.
Ausblick
BTRFS läuft Kernel 4.5 vom März 2016 auf dem Laptop stabil. Auch meine aktuellen privaten Server-VMs verwenden BTRFS im Dauerbetrieb, die Neueste bis auf das Dateisystem für /boot ausschließlich. Voraussichtlich kommt es für einen längeren Zeitraum zum Einsatz.
Allerdings beobachte seit einer Weile auch BCacheFS von Kent Overstreet, dem Entwickler von BCache. BCache – ab Version 3.10 im Linux-Kernel enthalten – ist ein Mechanismus, um langsame Block-Geräte, etwa Festplatten, durch schnellere Block-Geräte wie SSDs zu beschleunigen. Dem Entwickler wurde klar, wie er mit BCache bereits einiges an Grundlagen zu einem Dateisystem entwickelt hat. Mit Hilfe finanzieller Unterstützung von Spendern baute er BCache weitgehend im Alleingang zu einem vollwertigen Copy on Write-Dateisystem mit einem ähnlichen Funktionsumfang wie BTRFS oder ZFS aus. Prüfsummen und RAID-Funktionalität funktionieren schon, Snapshots brauchen noch Arbeit. Außerdem bietet BCacheFS aufgrund seiner Herkunft bereits nativ das Caching langsamerer durch schnellere Datenträger – eine Funktion, die in BTRFS immer noch nicht offiziell zur Verfügung steht.
Derzeit läuft der Review-Prozess, um BCacheFS schrittweise in den offiziellen Kernel aufzunehmen. Der LWN-Artikel „An update on bcachefs“ vom Mai 2018 erläutert nähere Hintergründe dazu. Auf dem Linux Storage, Filesystem, and Memory-Management Summit (LSFMM) in 2018 nannte Kent Overstreet Performance als wesentliche Eigenschaft von BCacheFS.
Das ist interessant, da BTRFS mit dem ständigen Schreiben in große Dateien selbst auf SSDs in der Regel nicht mit optimaler Performance arbeitet. Durch Copy on Write schreibt BTRFS die neuen Daten immer an eine neue Stelle, wodurch es die Datei stark fragmentiert. Die Abhilfe via Mount-Option autodefrag in Zeiten mit wenig Schreibzugriffen durch Anwendungen automatisch zu defragmentieren, schafft da nur teilweise Abhilfe. Inwiefern BCacheFS diesen Anwendungsfall trotz Copy on Write besser hinbekommt, habe ich noch nicht getestet.
Ebenfalls interessant ist der von Red Hat favorisierte Ansatz Stratis, das via Device Mapper für das XFS-Dateisystem Snapshots und Storage Pools bereitstellt. Es besteht aus einem via DBUS-API ansprechbaren Dienst und einem Befehl, um Stratis zu konfigurieren und zu steuern.
Unsere Schulungen
Mehr zu BTRFS und zu anderen Dateisystemen und zu Dateisystemen im Allgemeinen erzähle ich in unseren Linux-Schulungen Linux / UNIX Basics und Linux Advanced. Wer tiefer einsteigen möchte und die entsprechenden Vorkenntnisse hat, dem empfehle ich den Kurs Linux Performance Analyse- und Tuning bei qSkills oder der Heinlein Akademie.
Martin Steigerwald

Martin Steigerwald beschäftigt sich seit Mitte der 90er Jahre mit Linux. Er ist langjähriger Autor von Artikeln für verschiedene Computer-Magazine wie die LinuxUser (linuxuser.de) und das Linux-Magazin (linux-magazin.de). Seit Herbst 2004 ist er als Trainer für Linux-Themen bei Proact Deutschland in Nürnberg tätig.



